Search Preview
Data Dico
benheubl.github.ioJekyll2017-10-22T22:01:30+00:00https://benheubl.github.io/Data DicoData science and journalism blogBen Heubltechjournalism@gmail.comMethod to the madness -
.io > benheubl.github.io
SEO audit: Content analysis
| Language | Error! No language localisation is found. | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Title | Data Dico | ||||||||||||||||||||||||||||||||||||
| Text / HTML ratio | 99 % | ||||||||||||||||||||||||||||||||||||
| Frame | Excellent! The website does not use iFrame solutions. | ||||||||||||||||||||||||||||||||||||
| Flash | Excellent! The website does not have any flash contents. | ||||||||||||||||||||||||||||||||||||
| Keywords cloud |
|
||||||||||||||||||||||||||||||||||||
| Keywords consistency |
|
||||||||||||||||||||||||||||||||||||
| Headings | Error! The website does not use (H) tags. | ||||||||||||||||||||||||||||||||||||
| Images | We found 0 images on this web page. |
SEO Keywords (Single)
| Keyword | Occurrence | Density |
|---|---|---|
| 1920 |
96.00 % |
|
| class=w> | 1914 | 95.70 % |
class=p>| 1171 |
58.55 % |
|
class=o>=| 239 |
11.95 % |
|
| 191 |
9.55 % |
|
class=o>lt| 155 |
7.75 % |
|
class=o>| 141 |
7.05 % |
|
class=o>gt| 122 |
6.10 % |
|
| models | 118 | 5.90 % |
| model | 111 | 5.55 % |
| data | 89 | 4.45 % |
| speeches | 84 | 4.20 % |
| class=c1> | 81 | 4.05 % |
| ||
| text | 73 | 3.65 % |
| < | 62 | 3.10 % |
| run | 59 | 2.95 % |
| 59 |
2.95 % |
|
| > | 57 | 2.85 % |
| = | 49 | 2.45 % |
SEO Keywords (Two Word)
| Keyword | Occurrence | Density |
|---|---|---|
class=w> | 1877 |
93.85 % |
|
| class=p> | 685 | 34.25 % |
=| 206 |
10.30 % |
|
| class=o>= | 205 | 10.25 % |
| class=o>lt | 152 | 7.60 % |
lt| 151 |
7.55 % |
|
| class=o>gt | 121 | 6.05 % |
gt| 120 |
6.00 % |
|
| of the | 99 | 4.95 % |
| in the | 86 | 4.30 % |
| 75 |
3.75 % |
|
| 70 | 3.50 % | |
| class=o> | 70 | 3.50 % |
| 59 |
2.95 % |
|
| alt=alt text | 48 | 2.40 % |
| for the | 46 | 2.30 % |
| on the | 42 | 2.10 % |
class=n>library| 41 |
2.05 % |
|
class=p> | 41 |
2.05 % |
|
highlighterrouge>| 40 |
2.00 % |
|
SEO Keywords (Three Word)
| Keyword | Occurrence | Density | Possible Spam |
|---|---|---|---|
class=p> | 660 |
33.00 % |
No |
|
class=w> =| 206 |
10.30 % |
No |
|
class=o>= | 205 |
10.25 % |
No |
|
| = | 205 | 10.25 % | No |
class=o>lt | 152 |
7.60 % |
No |
|
class=w> lt| 150 |
7.50 % |
No |
|
| lt | 150 | 7.50 % | No |
class=o>gt | 121 |
6.05 % |
No |
|
class=w> gt| 120 |
6.00 % |
No |
|
| gt | 119 | 5.95 % | No |
| class=w> | 70 | 3.50 % | No |
class=o> | 70 |
3.50 % |
No |
|
class=w> | 70 |
3.50 % |
No |
|
| 66 | 3.30 % | No | |
class=w> | 52 |
2.60 % |
No |
|
highlighterrouge> | |||
class=languager highlighterrouge>| 37 |
1.85 % |
No |
|
| 37 |
1.85 % |
No |
|
= | 36 |
1.80 % |
No |
|
| 34 | 1.70 % | No |
SEO Keywords (Four Word)
| Keyword | Occurrence | Density | Possible Spam |
|---|---|---|---|
| class=w> = | 205 | 10.25 % | No |
= | 205 |
10.25 % |
No |
|
lt | 150 |
7.50 % |
No |
|
| class=w> lt | 150 | 7.50 % | No |
| class=w> gt | 119 | 5.95 % | No |
gt | 119 |
5.95 % |
No |
|
class=p> gt| 69 |
3.45 % |
No |
|
| 66 |
3.30 % |
No |
|
| class=w> | 66 | 3.30 % | No |
class=p> | 62 |
3.10 % |
No |
|
| class=p> | 51 | 2.55 % | No |
| 37 |
1.85 % |
No |
|
class=languager highlighterrouge> | |||
| 33 |
1.65 % |
No |
|
class=w> library| 32 |
1.60 % |
No |
|
| class=w> | 29 | 1.45 % | No |
class=p> library| 29 |
1.45 % |
No |
|
class=w> mutate| 28 |
1.40 % |
No |
|
class=o>gt mutate| 28 |
1.40 % |
No |
|
class=p> | 28 |
1.40 % |
No |
|
Internal links in - benheubl.github.io
Posts
Posts by Year - Data Dico
Posts by Year - Data Dico
About
Data Dico - Data Dico
Data Dico - Data Dico
Categories
Posts by Category - Data Dico
Posts by Category - Data Dico
2
Data Dico - Page 2
Data Dico - Page 2
Feed
Data Dico
Data Dico
Benheubl.github.io Spined HTML
Jekyll2017-10-22T22:01:30+00:00https://benheubl.github.io/Data DicoData science and journalism blogBen Heubltechjournalism@gmail.comMethod to the madness - How to write an Economist Leader2017-10-22T00:00:00+00:002017-10-22T00:00:00+00:00https://benheubl.github.io/analysis/leader<p><strong>A very unshared structure of the <a href="https://www.economist.com/sections/leaders">Economist Leader articles</a> emerges, without a shielding analysis</strong></p> <p><img src="https://benheubl.github.io/images/leader/intro.jpg" alt="pic1" /></p> <p>In this post, I aim to inspire other journalists and bloggers to wield the structure of the Economist leader to tell their own arguments.</p> <p>“The leader” is one of the most important products the magazine delivers every week for its print and online edition. A guide of its sonnet was shared by editors in a training session some time ago (I worked at the paper in the past). I want to share with you some of the lessons considering I think it could enrich the work of others in the profession.</p> <p>Before going deeper into its structure, a unenduring discussion on what a leader is in the vision of the paper: It is a device to tell the reader what is important, to help sharpen readers argument, and occasionally to transpiration their minds. For new and emerging journalists, it can be nonflexible to write it, says one editor. A well-spoken structure can be a remedy for any novice.</p> <h3 id="the-economist-uses-the-leader-for-two-reasons">The Economist uses the leader for two reasons:</h3> <ol> <li>Importance of current events: to help readers understand current important situations, while explaining an agenda</li> <li>Issues that faded into the background, but are worth it to dig up again: Events and topics that mostly aren’t news right now, but ought to be on readers’ agenda. It’s well-nigh saying that something matters, as much as it is well-nigh how suspiring its conclusion is.</li> </ol> <p>A shorter unravelment is offered: “If pieces are stories, leaders are arguments”. There is a sense of importance and this is why, many times, leader arguments make it on the cover.Imbricatestory and leaders are connected.</p> <p>The leader wants to help readers to form their arguments. There are a number of ways those arguments are of importance. One of those argument-types is often referred to as “mind caring”. This is mainly well-nigh untangling the mess of a specific event (see the leaders on Donald Trump, protectionism, major despots of our time … - the list is long).</p> <p>It is moreover often the province of economic leaders, where many times contradictory arguments are stuff tabbed out. Those leaders help to understand what’s important, and which of those matter most and are likely to win a debate.</p> <p>The second type of leader is the “missing the point leader”. Those will make the treatise that the real problem virtually a topic is in fact veiled somewhere else. Those leaders are fruitful, as one editor says. The leader on unintended consequences is a growing and rich theme (regulations that are supposed to make the world safer, but in fact have little or the opposite effect).</p> <p>The Dodd Frank act, and the unintended consequences on the intent to skiver the regulation, is an <a href="https://www.economist.com/news/leaders/21716607-make-rules-simpler-all-means-not-expense-safety-right-way-redo">older example</a>. Some of the weightier leaders written on values sally from that direction.</p> <p>A leader on murder wouldn’t be right and is likely wearisome - stuff wearisome is a strategic sin, says one editor. The weightier leaders for example well-nigh values have the worthiness to surprise. Leaders on ethics, that have a counterintuitive or surprising conclusion (e.g. a leader on legalising prostitution).</p> <h2 id="structure">Structure</h2> <p>Usually, a leader covers a number of vital elements. Sometimes authors decide to leave out components, sometimes towers blocks towards in a slightly variegated way or sequence.</p> <p>The vital components of a leader in the pursuit sequence:</p> <p><strong>1. Introduction: The start contains an enticing observation, and the theme -> 2. News/contemporary event -> 3. The nub -> 4. Stand when -> 5. Your arguments -> 6. Their arguments -> 7. What to do well-nigh it</strong></p> <p>While explaining each, let’s talk well-nigh an <a href="https://www.economist.com/news/leaders/21730409-how-workplaces-can-rid-themselves-pests-and-predators-capitalist-case-against-sexual">example</a> from the current edition.</p> <p><img src="https://benheubl.github.io/images/leader/sex_haras.png" alt="pic1" /></p> <h2 id="1-introduction">1. Introduction:</h2> <p>Most leaders uncork with an observation, scrutinizingly never is the start a statement of the news peg (it rarely works considering it seems flat). Those very first thoughts are many times of an emotional nature.</p> <p>They can be moving, funny and are enticing. Many times they go versus the conclusion, may plane provoke and correlate with the public opinion. Usually they are short, a little paragraph, both relevant and fitting to the cadre argument(s).</p> <p>The second component for the introduction is to state the theme; or answering: “What is this all about?”</p> <h2 id="2-newscontemporary-event">2. News/contemporary event:</h2> <p>Here the tragedian drops the news-peg. In the specimen of the “Sex and power” leader, it is New York Times investigation into Harvey Weinstein and his response to the allegations.</p> <h2 id="3-the-nub---the-punctuation-point-that-sets-up-everything-else-to-come">3. The nub - the punctuation point that sets up everything else to come:</h2> <p>Often missing, the first section of the leader ends with the nob. It is stuff described as giving the leader its momentum, the bit of tension in the treatise and the part where the tragedian states what’s wrong. An example is where the tragedian of “Sex and power” writes: “A throwback who loves women too much, then; a sly old rogue who doubtless holds doors unshut for women, too? Nonsense. What Mr. Weinstein is accused of was never acceptable. It has never been good form to greet a woman arriving for a merchantry meeting while wearing nothing but an unshut bathrobe”.</p> <p>In a post piece, this bit can be included too, but usually remoter down. The characteristics of the leader pulls this section up, near the whence (many times, it is right surpassing the first crosshead, in our specimen surpassing the crosshead “NotUnscratchedFor Women” - the crosshead marks usually the purlieus between first section and rest). The nob draws readers in, and explains why to read this leader - REALLY, Weinstein’s policies was never acceptable.</p> <h2 id="4-stepping-back-and-giving-context-and-background">4. Stepping-back and giving context and background:</h2> <p>This is the point when the tragedian explains the context, historical entanglements and the endangerment to elaborate how we got here. For politics, many times readers get a history lesson. For an economics and merchantry leader such as “Sex and power”, we are told well-nigh the 1970ties and 1980ties and offices with “Mad Men-style ordeal of leering vision and roaming hands”.</p> <h2 id="5-and-6-deploy-a-balance-of-arguments">5. and 6. Deploy a wastefulness of arguments:</h2> <p>Here, the tragedian positions the arguments. Data journalists particularly, may enjoy their bit of fun at this point permitting to waif their statistical theses and throw virtually arguments based on numbers. Showing both, yours and theirs is crucial. Set a wastefulness between pro and contra arguments while keeping it unenduring (usually, each paragraph here is a single argument).</p> <p>One editor says that an tragedian thoughtfully takes on the opponent’s argument, which usually a tropical observation of the pro-arguments can overtrump. As one editor explains, this section is an important part of the leader where the authors grapple with the good arguments versus the overall treatise - a notion that makes the leader a good and powerful medium for journalism. It requires to retain a pearly view on a topic.</p> <h2 id="7-last-bit-of-the-leader-the-prescription">7. Last bit of the leader: The prescription</h2> <p>This section describes the mess is short and offers possible solutions - an opportunity to respond to the hodgepodge of both sides of an treatise - increasingly importantly may urges the tragedian to segregate the very weightier treatise and respond with the weightier bet of a solution.</p> <p>For “Sex and Power”, it is the bit where the tragedian likens sexual harassment with homophobic remarks. For sexual harassment to be stopped, it needs to be tabbed out in the same way, not just by the victims, but moreover by the witnesses.</p> <p>Each leader’s narrative usually finance for one page, virtually the 1,000 word mark (many times the topic are remoter extended in other parts of the paper). Elections, Brexit, industries in transformation, and Tech, all those are instances of topics leaders can embrace. They are brazing and prevailing wires in the present news-landscape. To a greater or lesser extent, a leader settles a score with a person, an event or a trend, which usually isn’t just going yonder tomorrow or next week.</p> <p>With the medium of those leaders, there is one of the company’s most important products: a exegesis of how to fathom the world. The magazine moreover delivers those in a single voice – there are no bylines.</p> <p>Hoping not to share too much of the secret sauce of the magazine that I revere very much for its work, I can only fathom those lessons and use some of the idea for my own work.</p> <!-- <figure> <a href="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg"> <img src="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg"> </a> <figcaption><a href="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg" title="Street League 2013: Nyjah Huston">Street League 2013: Nyjah Huston</a>.</figcaption> </figure> --> <!-- Skateboarding has had a bad reputation for many years surpassing Louis Vuitton used [it in their ads](https://www.youtube.com/watch?v=GWydT-BNbQo). Today, skateboarding manages to get sustentation from all corners of the media landscape, and is now plane only one step yonder to wilt an [Olympic discipline](http://theridechannel.com/news/2016/06/skateboarding-olympics-tokyo-2020). For decades, the typical competition format was that skaters were judged on their run, however Street league Skateboarding established a whole new data driven model to judge the performance of each street skater. Instead of only stuff ranked on the run on the skate course, SLS introduced a real time rating system, single tricks evaluation, and a statistical evaluation of the scoring for each skater.  # Sh.t is going lanugo this weekend, at the Nike SB Super Crown World Championship This Sunday, the biggest street skateboarding competition will take place in LA. SLS is the official street skateboarding world championship as recognized by the International Skateboarding Federation. At the recent Street League Skateboarding Nike SB World Tour in Newark, New Jersey, [Nyjah Huston](http://streetleague.com/pros/nyjah-huston/) won the game and is now defending the 2015 SLS Championship title. Could we yield some interesting findings that could support skaters with empirical vestige how to win it?  Via a simple [EDA](https://en.wikipedia.org/wiki/Exploratory_data_analysis), we will try to establish a number of relevant patterns gained from previous SLS results. # Relationships We understand from the correlation plot that there is a negative relationship between best-trick and run scores (-0.5), and an interesting one between age of skater and number of sponsors for each skater. Number of sponsors moreover plays nicely with final results for 2015 championship points.  # Strategy Loess line seems to yank a variegated picture, than the linear regression line. We will consider the structure later, when towers a prediction model. SLS's competition format requires a lot increasingly strategic planning today, than in the previous single score run-based competitions. An wringer of run-section and best-trick scores wideness recent Street League contests suggests that if players do perform well on either one of the sections, they usually perform not not as well in the other one (although, the linear trend is increasingly significant for the preliminaries).  Chaz Ortiz and Shane O'Neill know how to perform well in the run section (mainly due to their vast wits in conventional skate contests), while Kevin Hoefler and Manny Santiago do well in the best-trick section. All-rounders such as Nyjah Huston and Luan Oliveira seem to do well in both sections for the finals. For the preliminaries, Shane and Nyjah leading the field, and are worldly-wise to make it into the finals every single time. # Street League's incubation Launched in 2010, Street League Skateboarding is now an international competitive series in professional skateboarding. The SLS ISX, which is the cadre of the concept, is weightier described as a real time scoring system, permitting to include each trick independently. This stands in unrelatedness to all other professional contests that judge on overall impression of a full run or series of tricks performed within a unrepealable time frame.Consideringthe outcome could transpiration to the very last trick, the regulars is kept in their seats. Transparency is upper too. If the regulars is worldly-wise to understand how and why the skaters were judged the way they were, it adds an spare kick. To win, skaters are required to to have a strategy and be smart well-nigh how they play their skills and their endurance.  Comparing 2015 with 2016, Nyjah Huston's run scores dropped slightly (this could be due to the fact that the scoring reverted overall).  While Shane O'Neill could not modernize on his highest run scores (but on weightier trick scores)... 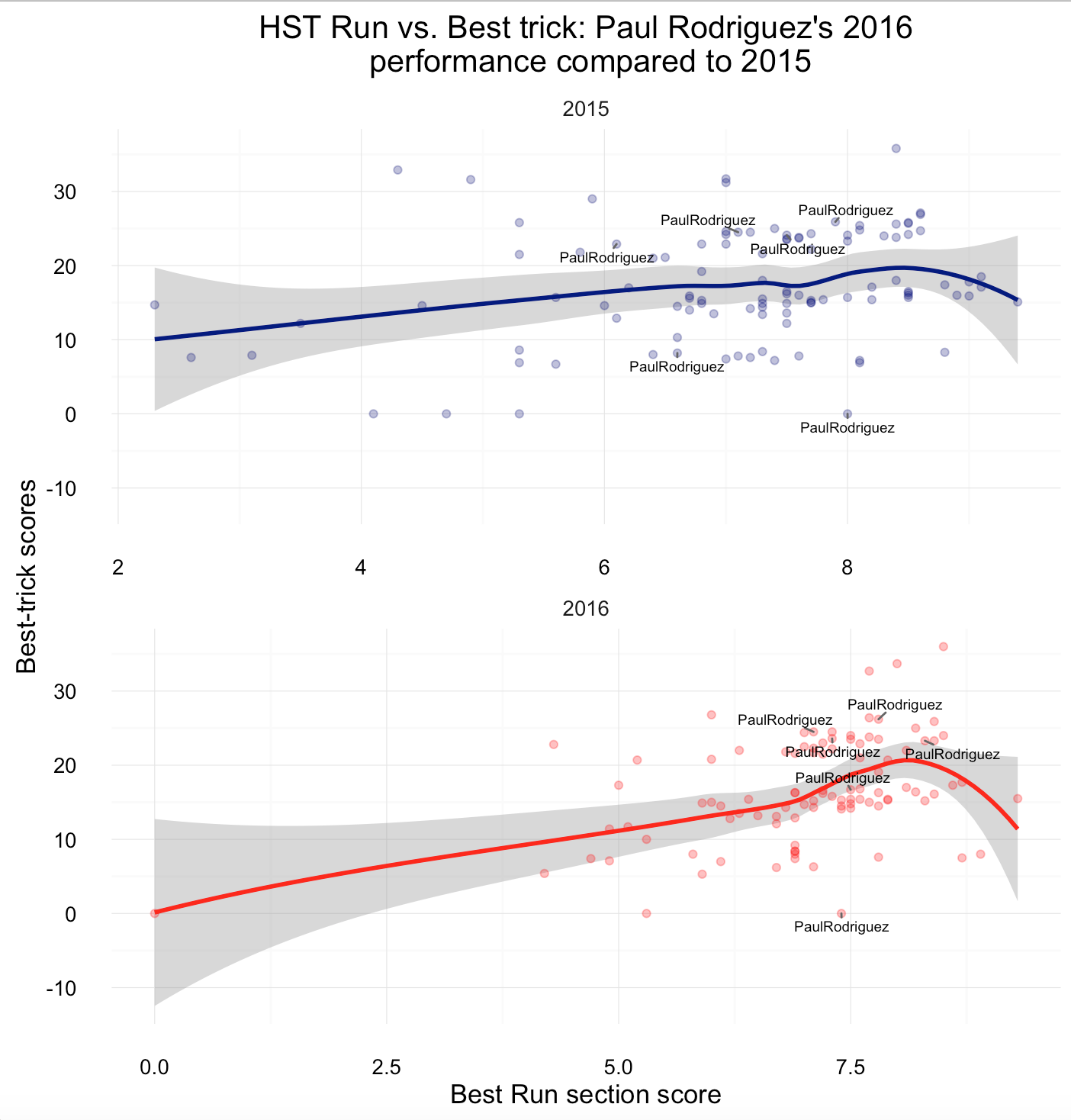 ...Paul Rodriguez kept performing well wideness both sections. If a skater is strikingly good at the run section, but fails to succeed in the weightier trick section (or vice versa), he (or she, sexuality Street League was introduced in 2015) is unlikely to win. So what is the weightier strategy? To wordplay the question, it helps to squint at statistical coefficients and relationships for data points for the previous events. # Can you predict win probabilities without the run section? Ok, we learned something from a vital exploratory data analysis. It's time to shift our sustentation to machine learning and use what we learned. Every SLS game starts with the run section, and ends with the weightier trick category. We could use machine learning and train one or multiple models to yield win probabilities without the run section, but surpassing the weightier trick section and utterance of a winner to predict the winner. In the next part our goal is to build multiple models, the practice to statistically compare them, and to come up with one that allows us to predict mid-game, which skater has the weightier changes to win the upcoming SLS Nike SB Super Crown World Championship. ## DefiningSelf-sustainingand dependent variables The outcome variable we will predict is a win or no-win. An variation to this is towers a nomenclature models on podium winners (1st, 2nd, 3rd). In variegated corner of the SLS website, we find information on the [pro skaters](http://streetleague.com/pros/), their previous performances and [event-specific results](http://streetleague.com/coverage/new-jersey-2016/). From the [SLS website](http://streetleague.com/the-9-club/), we scrape the number of 9 club scores for each skater (9 Club tricks are the most no-go moments in Street League and represents the highest scores in previous contest). 9 club scores may moreover be an important predictor on how well the players did perform in the weightier trick section. Run HST and Run Avg may be important predictors to our models. Championship Points indulge new and established skaters to qualify into the SLS Nike SB Super Crown World Championship. Each skater's point score will be fed to our model. We moreover throw in spare parameters. We have wangle to the age of some of the established pro skaters (the stereotype age of pros is virtually 25, but outliers such as Cole may skew it), we know their stance (goofy or regular), and in the process of scraping and cleaning, I was worldly-wise to count the number of sponsors. # Model types We will build logic regression nomenclature models, and compare how well they are worldly-wise to perform versus each other. ## Logic Regression We will build and test a [binomial logistic regression](https://en.wikipedia.org/wiki/Binomial_regression) (our outcome variable which can seem 2 values). The pursuit variables will be used to fit a [GLM](https://stat.ethz.ch/R-manual/R-devel/library/stats/html/glm.html) model in R: ```r # Overview of variables: glimpse(win) ``` In a subconscious process, I have cleaned the data, and converted them to required matriculation types.Well-defineddata are factor values, while numerical are encoded as numerical or as an integer class. The age variable has no missing values anymore ([removal of NA values in R](http://stackoverflow.com/questions/7706876/remove-na-values-from-a-vector)), and they have been replaced with the stereotype age values. Similarly, I dealt with the values in the stance post (to what stratum this is valid, needs to be evaluated, but for now, we don't superintendency too much well-nigh stance - in theory, it shouldn't make a difference whether a sunny skater is goofy or regular). 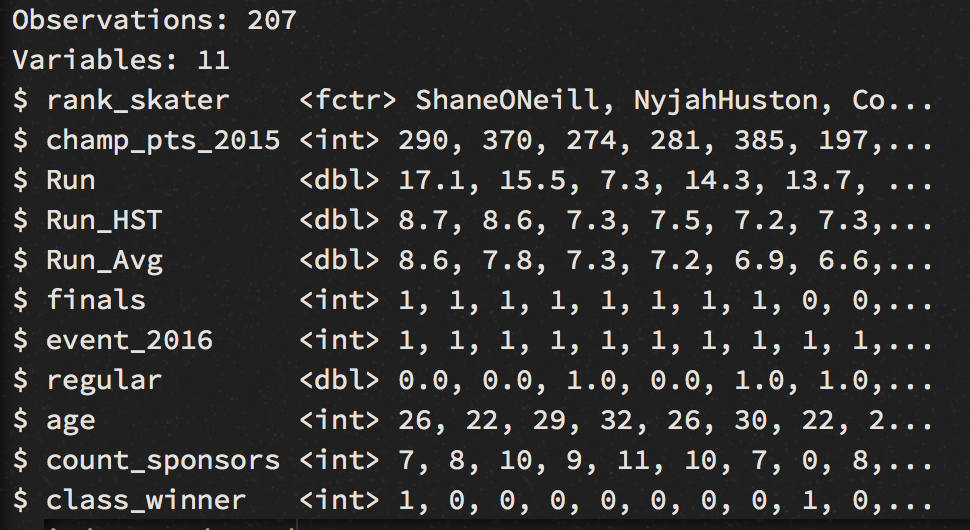 ```r # randomize, sample training and test set: set.seed(10) win_r <- sample_n(win, 207) train <- win_r[1:150,] test <- win_r[151:207,] # fit GLM model: model <- glm(class_winner ~.,family=binomial(link='logit'),data=train) summary(model) ``` 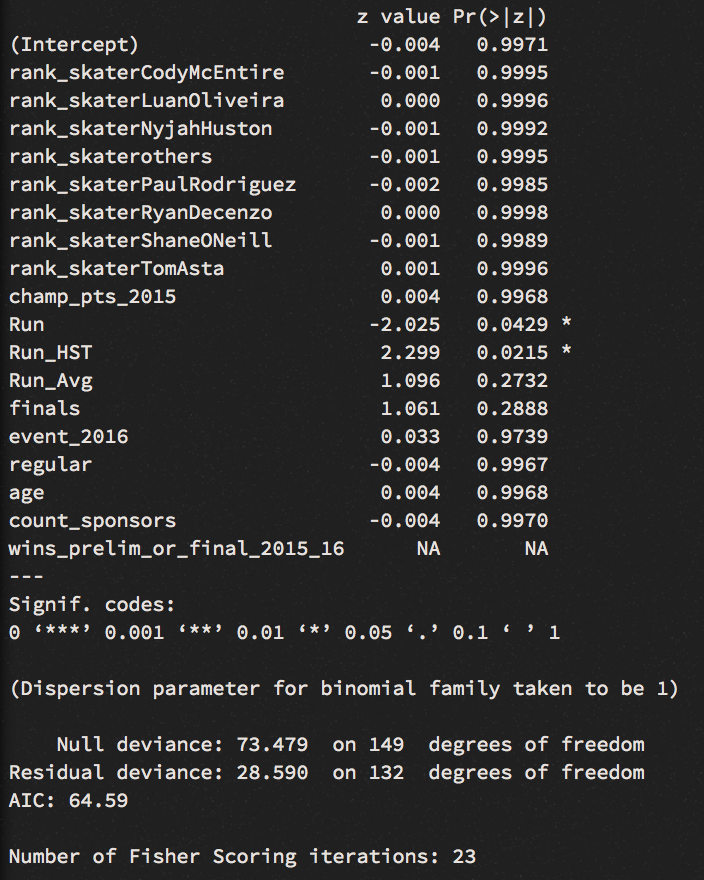 We learn from the summary function that most of the variables are not statistically significant for our model. Run_HST is possibly the weightier predictor we can use at this stage. A positive coefficient for Run_HST suggests - if other variables are kept equal - that a unit increase in highest run section scores would increase the odds to win by 4.740e+00. We run a function from the Anova package, to investigate the table of deviance: ```r anova(model, test="Chisq") ``` 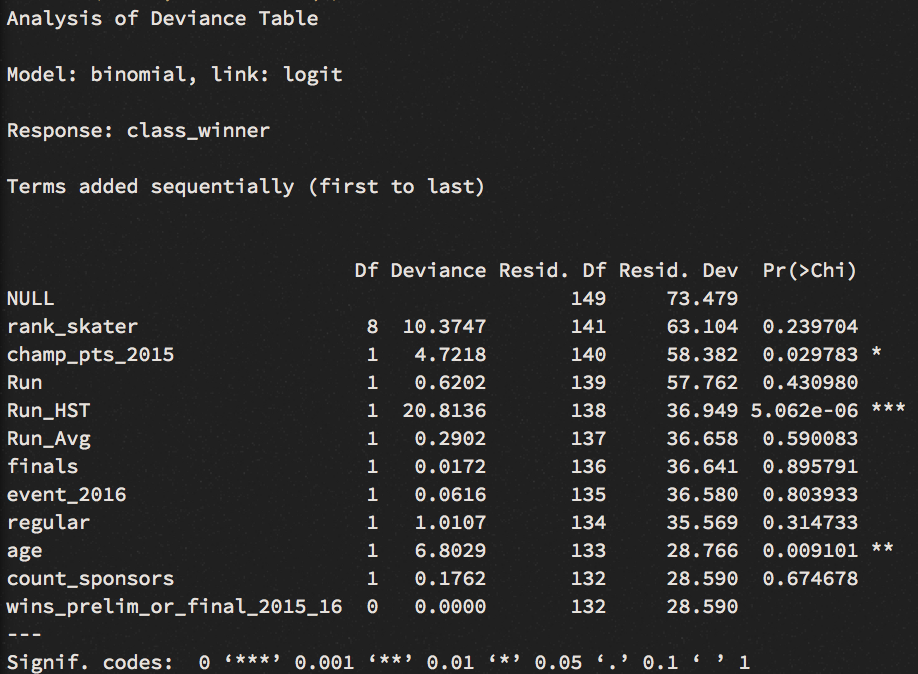 This gives us an idea on how well our GLM model performs agains the null model. Here we see that not only Run_HST reduced the residual deviance, but moreover the variables age and champ_pts_2015\. For us it is important to see a significant subtract in deviance. Lets assess the model's fit via McFadden R-Squared measure: ```r install.packages("pscl") library(pscl) pR2(model) llh llhNull G2 McFadden r2ML r2CU -14.2949557 -36.7395040 44.8890966 0.6109105 0.2586338 0.6678078 ``` This yields a McFadden score of 0.611, which might be comparable to a linear regression's R-Squared metric. ```r # Run on test data: test_run<-test %>% select(-class_winner) fitted.results <- predict(model,test_run, type='response') fitted.results <- ifelse(fitted.results > 0.5,1,0) misClasificError <- mean(fitted.results != test$class_winner) misClasificError print(paste('Accuracy',1-misClasificError)) #[1] "Accuracy 0.912280701754386" #CrossTable: CrossTable(fitted.results, test$class_winner, prop.chisq = F, prop.t = F, dnn = c("Predicted", "Actual")) ``` While we get an verism of 91%, this result is misleading. The model couldn't find who is going to win. Only who is not to win, which isn't really our problem at this stage, but one reason we get such upper verism score. 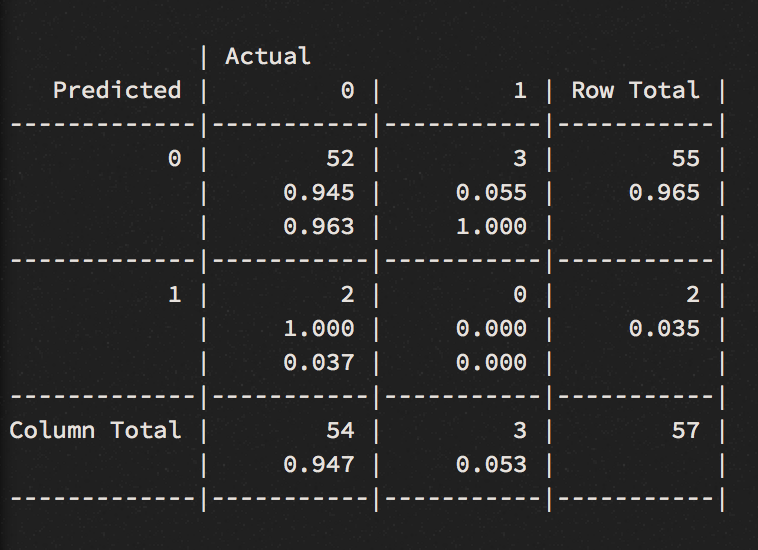 ```r ctrl <- trainControl(method = "repeatedcv", number = 10, savePredictions = TRUE) mod_fit <- train(class_winner ~., data=win_r, method="glm", family="binomial", trControl = ctrl, tuneLength = 5) pred = predict(mod_fit, newdata=test) confusionMatrix(data=pred, test$class_winner) ``` We can personize the verism result with K-Fold navigate validation, a inside model performance metric in machine learning. We wield one of the most worldwide variation of navigate validation, the 10-fold cross-validation and exhibit the result via a ravages matrix. Now we get an plane higher verism score of 95 percent. Still, the model couldn't find the winners. 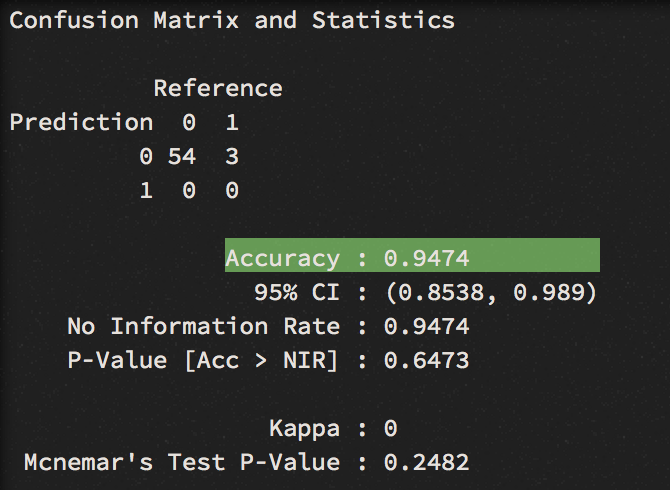 ## Predicting winning a medal: The data only covers two years of the games. This makes it nonflexible for a model like this to spot winners. What we could be doing instead is to tune lanugo our standards, and only squint for the lucky three winners who make it onto a podium. For that, we need to summate an uneaten column, and add a "1", for all skaters who made it among the top three, and "0" for the ones that didn't. To test our new model, we will run it on the most recent game in New Jersey, without cleaning the training data. ```r set.seed(10) win_r <- sample_n(test <- win[c(1:68, 77:207),], 199) train <- win_r test <- win[69:76,] ##New-Jersey-2016 model <- glm(top_3_outcome ~.,family=binomial(link='logit'),data=train) test_run<-test %>% select(-top_3_outcome) fitted.results <- predict(model,test_run, type='response') fitted.results <- ifelse(fitted.results > 0.5,1,0) misClasificError <- mean(fitted.results != test$top_3_outcome) print(paste('Accuracy',1-misClasificError)) #[1] "Accuracy 0.75" #CrossTable: CrossTable(fitted.results, test$top_3_outcome, prop.chisq = F, prop.t = F, dnn = c("Predicted", "Actual")) ``` 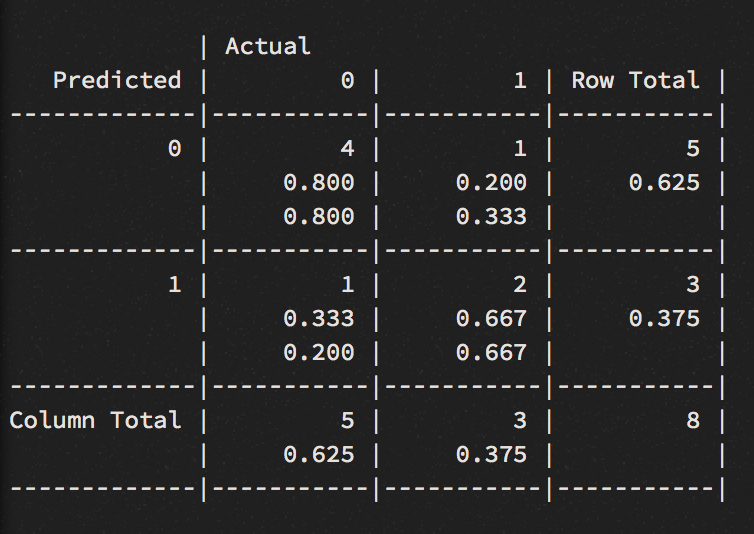 This model performs better. Except of 2 miss-classified instances, we got 2 out of 3 podium winners right. While it did well on the two winners - Nyjah Huston (1st), Chris Joslin (2nd), with 90% and 80% probability respectively - the model could not icon out the third place, that was labelled as "other" in our training data. Tommy Fynn was not included in the practice when I labelling the rank_skater post (skaters that will play Sunday's finals were labelled in the data). As good practice requires, we will squint at is ROC lines to produce a visual representation for the AUC, a performance measurements for a binary classifier. ```r install.packages("ROCR") library(ROCR) fitted.results <- predict(model,test_run, type='response') fitted_for_ROCR <- prediction(fitted.results, test$top_3_outcome) performance_ROCR <- performance(pr, measure = "tpr", x.measure = "fpr") # plot: plot(prf) AUC <- performance(fitted.results, measure = "auc") AUC <- auc@y.values[[1]] #[1] 0.7333333 ``` 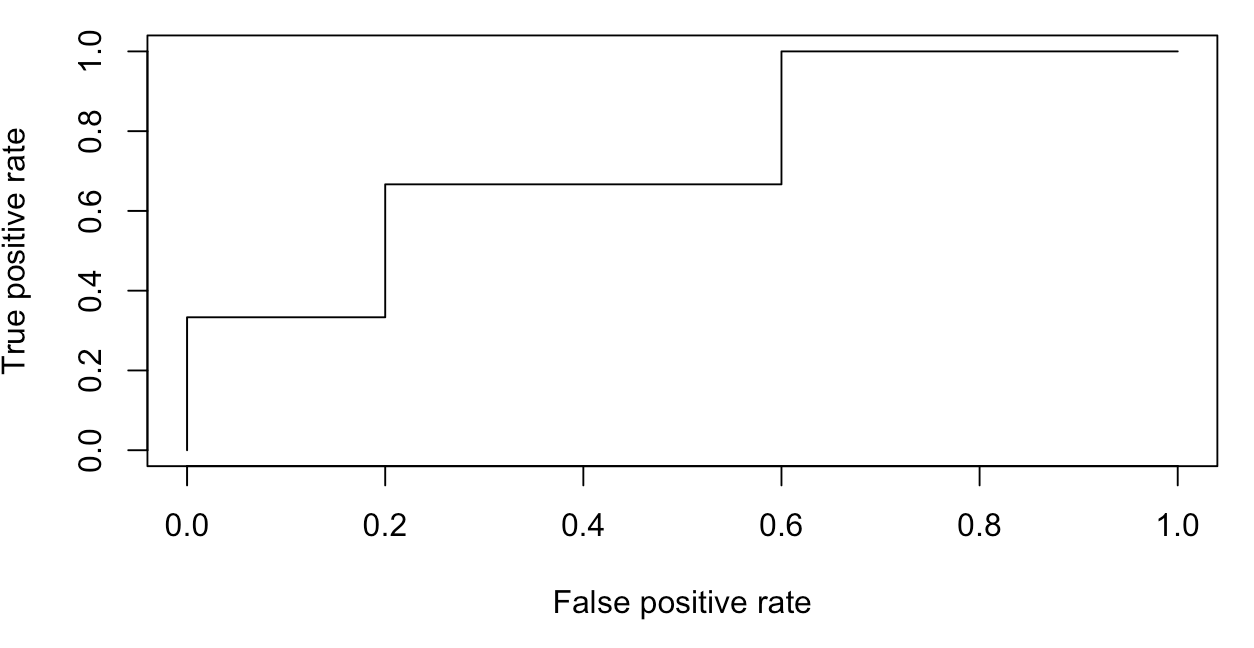 An AUC of 0.73 is not entirely pleasing, but it's a start. We could now squint for which score each skater on Sunday would need to proceeds for decent win probability. For this, we could build a test-set with the skater names and run scores ranging from 1 to 10 (we once know that skater and Run_HST are powerful predictors for the podium medals). ```r ### probabilities for highest scores: scores <- seq(1, 10, 0.1) skaters <- c("NyjahHuston", "ShaneONeill", "PaulRodriguez", "LuanOliveira", "TomAsta", "RyanDecenzo", "CodyMcEntire", "ChrisJoslin") df_skate <- NULL for (skater in 1:length(skaters)) { for (s in 1:length(scores)) { df_skate <- rbind(df_skate, cbind(as.data.frame(scores[s]), as.data.frame(skaters[skater]))) } } names(df_skate)[1] <- "Run_HST" names(df_skate)[2] <- "rank_skater" fitted.results <- predict(model,df_skate, type='response') # with Run_HST and rank_skater as input variables ggplot(props, aes(Run_HST, fitted.results, group = rank_skater, col = rank_skater)) + geom_line() + theme_minimal() ``` 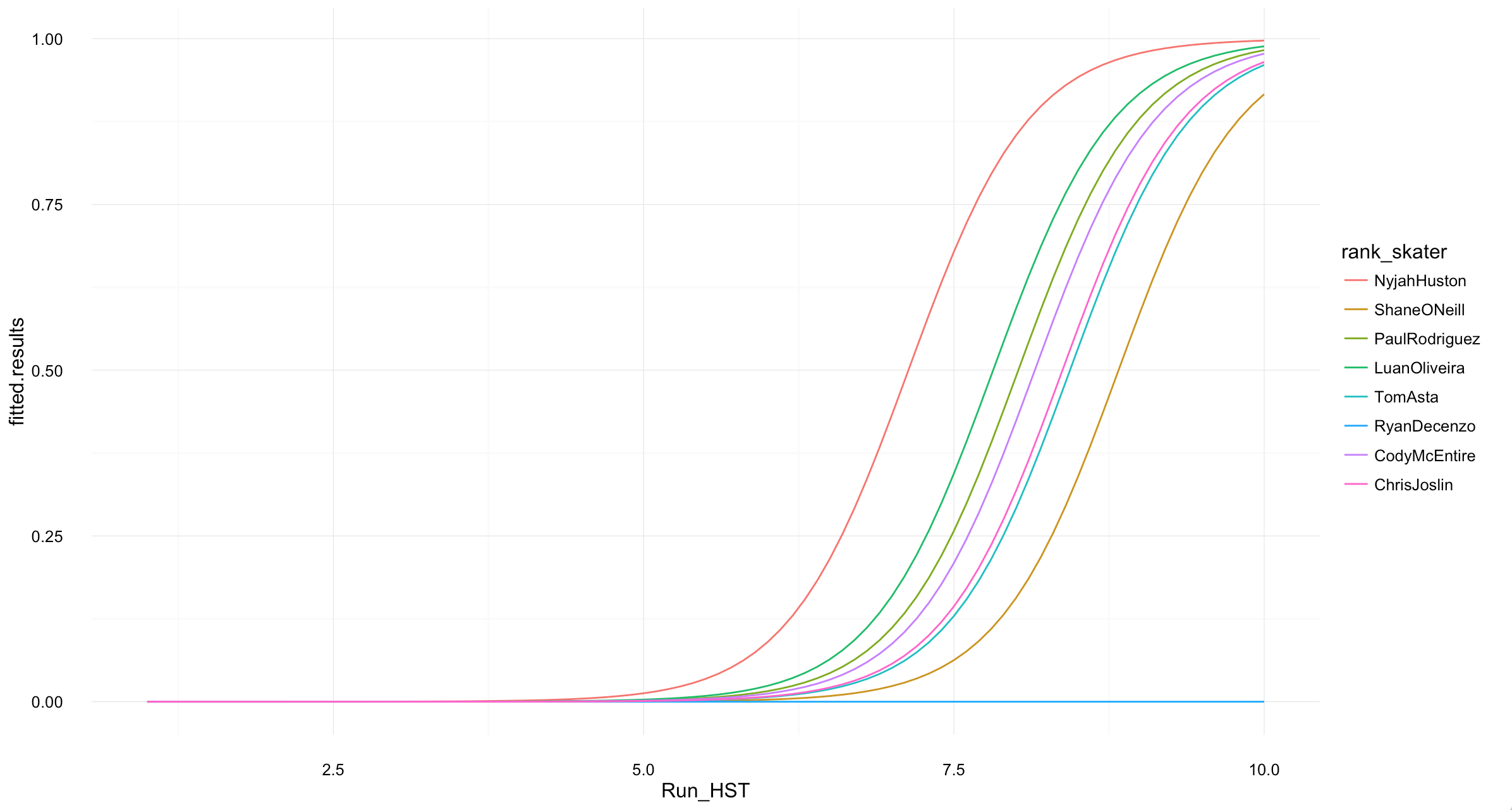 Win probabilities orchestration for each skater from their highest run scores. # Wrapping up As we have seen, Nyjah Huston, Shane O'Neill and Paul Rodriguez do have weightier chances to make it on the podium. In which combination is unclear, but we will find out shortly. We have moreover learned how to wield a logistic regression on skateboarding, and how to compare the results wideness the various types of models we build. Two increasingly models have been built. A neural network model and a random forrest model, both which didn't perform as well as the logistic regression. -->Ben Heubltechjournalism@gmail.comA very unshared structure of the Economist Leader wares emerges, without a shielding analysisHow does the education of your parents relate to that of your spouse?2017-04-09T00:00:00+00:002017-04-09T00:00:00+00:00https://benheubl.github.io/analysis/education_spouse_parents<p><strong>The Level of education plays a significant role in how we segregate a partner. But how does the level of education of our parents relate to how Americans marry? It turns out that the gap of length of education between spouse and parents used to shrink and now seemed to have stopped remoter converge.Moreoverthe wringer shows that mothers used to shepherd school longer than fathers in the past, but the reverse is true today.</strong></p> <p><img src="https://benheubl.github.io/images/gss1/A1.png" alt="pic1" /></p> <p>Men and women tend to segregate one flipside with <a href="http://www.jstor.org/pss/10.1086/660108">similar educational achievements in mind</a>. Yet, since educational achievements are many times supported - one could say “pushed” – by parents and their achievements, I was interested in how parents’ education compared with those of peoples’ spouses.</p> <p><a href="http://gss.norc.org/">TheUnstipulatedSocial Survey</a> offers data that goes all the way when to the 1970ies and consists of 62,466 responses wideness various questions. Interesting for this piece is how respondents answered to the questions of how many years their father, their mother and their spouse went to school.</p> <p>The stereotype spouse in 2016 went to school 14.13 years, 2.2 years longer than his or her parents. 44 years ago, this difference was much larger. The theorizing is that older generations had fewer opportunities. In 1972, people chose a spouse with a school career of 12 years on average. The gap between spouse and parents rumored for 3.15 years. The difference shrunk over the years, logical so, as generations developed.</p> <p>Slowly over time, both current and past generation could pursue the same opportunities in education. Yet, within the last ten year, this contracting trend seems to have come to a halt and flattened (note the polynomial trend line). The convergence stagnates at 2.25 years of schooling. Now, this could have multiple explanations, which require increasingly research. But the fact that the trend slows, should be noticed.</p> <p><img src="https://benheubl.github.io/images/gss1/A2.png" alt="pic1" /></p> <p>A second observation concerns only the parents. It looks at the difference between fathers and mothers’ reported periods of schooling. The wringer revealed that mothers were reported to have spent longer at school on stereotype until 2003. From 2004 onwards, the trend reverses and fathers have a longer schooling career.</p> <p>Since 2004, fathers are reported to shepherd school 0.11 years longer than mothers. Note how the trend-line suggest a cooling, seemingly settling at the mark of 0.125 years or 45 days, fathers spend longer swotting than mothers. What does this mean? Email me, I am hooked to find out.</p> <!-- <figure> <a href="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg"> <img src="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg"> </a> <figcaption><a href="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg" title="Street League 2013: Nyjah Huston">Street League 2013: Nyjah Huston</a>.</figcaption> </figure> --> <!-- Skateboarding has had a bad reputation for many years surpassing Louis Vuitton used [it in their ads](https://www.youtube.com/watch?v=GWydT-BNbQo). Today, skateboarding manages to get sustentation from all corners of the media landscape, and is now plane only one step yonder to wilt an [Olympic discipline](http://theridechannel.com/news/2016/06/skateboarding-olympics-tokyo-2020). For decades, the typical competition format was that skaters were judged on their run, however Street league Skateboarding established a whole new data driven model to judge the performance of each street skater. Instead of only stuff ranked on the run on the skate course, SLS introduced a real time rating system, single tricks evaluation, and a statistical evaluation of the scoring for each skater.  # Sh.t is going lanugo this weekend, at the Nike SB Super Crown World Championship This Sunday, the biggest street skateboarding competition will take place in LA. SLS is the official street skateboarding world championship as recognized by the International Skateboarding Federation. At the recent Street League Skateboarding Nike SB World Tour in Newark, New Jersey, [Nyjah Huston](http://streetleague.com/pros/nyjah-huston/) won the game and is now defending the 2015 SLS Championship title. Could we yield some interesting findings that could support skaters with empirical vestige how to win it?  Via a simple [EDA](https://en.wikipedia.org/wiki/Exploratory_data_analysis), we will try to establish a number of relevant patterns gained from previous SLS results. # Relationships We understand from the correlation plot that there is a negative relationship between best-trick and run scores (-0.5), and an interesting one between age of skater and number of sponsors for each skater. Number of sponsors moreover plays nicely with final results for 2015 championship points.  # Strategy Loess line seems to yank a variegated picture, than the linear regression line. We will consider the structure later, when towers a prediction model. SLS's competition format requires a lot increasingly strategic planning today, than in the previous single score run-based competitions. An wringer of run-section and best-trick scores wideness recent Street League contests suggests that if players do perform well on either one of the sections, they usually perform not not as well in the other one (although, the linear trend is increasingly significant for the preliminaries).  Chaz Ortiz and Shane O'Neill know how to perform well in the run section (mainly due to their vast wits in conventional skate contests), while Kevin Hoefler and Manny Santiago do well in the best-trick section. All-rounders such as Nyjah Huston and Luan Oliveira seem to do well in both sections for the finals. For the preliminaries, Shane and Nyjah leading the field, and are worldly-wise to make it into the finals every single time. # Street League's incubation Launched in 2010, Street League Skateboarding is now an international competitive series in professional skateboarding. The SLS ISX, which is the cadre of the concept, is weightier described as a real time scoring system, permitting to include each trick independently. This stands in unrelatedness to all other professional contests that judge on overall impression of a full run or series of tricks performed within a unrepealable time frame.Consideringthe outcome could transpiration to the very last trick, the regulars is kept in their seats. Transparency is upper too. If the regulars is worldly-wise to understand how and why the skaters were judged the way they were, it adds an spare kick. To win, skaters are required to to have a strategy and be smart well-nigh how they play their skills and their endurance.  Comparing 2015 with 2016, Nyjah Huston's run scores dropped slightly (this could be due to the fact that the scoring reverted overall).  While Shane O'Neill could not modernize on his highest run scores (but on weightier trick scores)...  ...Paul Rodriguez kept performing well wideness both sections. If a skater is strikingly good at the run section, but fails to succeed in the weightier trick section (or vice versa), he (or she, sexuality Street League was introduced in 2015) is unlikely to win. So what is the weightier strategy? To wordplay the question, it helps to squint at statistical coefficients and relationships for data points for the previous events. # Can you predict win probabilities without the run section? Ok, we learned something from a vital exploratory data analysis. It's time to shift our sustentation to machine learning and use what we learned. Every SLS game starts with the run section, and ends with the weightier trick category. We could use machine learning and train one or multiple models to yield win probabilities without the run section, but surpassing the weightier trick section and utterance of a winner to predict the winner. In the next part our goal is to build multiple models, the practice to statistically compare them, and to come up with one that allows us to predict mid-game, which skater has the weightier changes to win the upcoming SLS Nike SB Super Crown World Championship. ## DefiningSelf-sustainingand dependent variables The outcome variable we will predict is a win or no-win. An variation to this is towers a nomenclature models on podium winners (1st, 2nd, 3rd). In variegated corner of the SLS website, we find information on the [pro skaters](http://streetleague.com/pros/), their previous performances and [event-specific results](http://streetleague.com/coverage/new-jersey-2016/). From the [SLS website](http://streetleague.com/the-9-club/), we scrape the number of 9 club scores for each skater (9 Club tricks are the most no-go moments in Street League and represents the highest scores in previous contest). 9 club scores may moreover be an important predictor on how well the players did perform in the weightier trick section. Run HST and Run Avg may be important predictors to our models. Championship Points indulge new and established skaters to qualify into the SLS Nike SB Super Crown World Championship. Each skater's point score will be fed to our model. We moreover throw in spare parameters. We have wangle to the age of some of the established pro skaters (the stereotype age of pros is virtually 25, but outliers such as Cole may skew it), we know their stance (goofy or regular), and in the process of scraping and cleaning, I was worldly-wise to count the number of sponsors. # Model types We will build logic regression nomenclature models, and compare how well they are worldly-wise to perform versus each other. ## Logic Regression We will build and test a [binomial logistic regression](https://en.wikipedia.org/wiki/Binomial_regression) (our outcome variable which can seem 2 values). The pursuit variables will be used to fit a [GLM](https://stat.ethz.ch/R-manual/R-devel/library/stats/html/glm.html) model in R: ```r # Overview of variables: glimpse(win) ``` In a subconscious process, I have cleaned the data, and converted them to required matriculation types.Well-defineddata are factor values, while numerical are encoded as numerical or as an integer class. The age variable has no missing values anymore ([removal of NA values in R](http://stackoverflow.com/questions/7706876/remove-na-values-from-a-vector)), and they have been replaced with the stereotype age values. Similarly, I dealt with the values in the stance post (to what stratum this is valid, needs to be evaluated, but for now, we don't superintendency too much well-nigh stance - in theory, it shouldn't make a difference whether a sunny skater is goofy or regular).  ```r # randomize, sample training and test set: set.seed(10) win_r <- sample_n(win, 207) train <- win_r[1:150,] test <- win_r[151:207,] # fit GLM model: model <- glm(class_winner ~.,family=binomial(link='logit'),data=train) summary(model) ```  We learn from the summary function that most of the variables are not statistically significant for our model. Run_HST is possibly the weightier predictor we can use at this stage. A positive coefficient for Run_HST suggests - if other variables are kept equal - that a unit increase in highest run section scores would increase the odds to win by 4.740e+00. We run a function from the Anova package, to investigate the table of deviance: ```r anova(model, test="Chisq") ```  This gives us an idea on how well our GLM model performs agains the null model. Here we see that not only Run_HST reduced the residual deviance, but moreover the variables age and champ_pts_2015\. For us it is important to see a significant subtract in deviance. Lets assess the model's fit via McFadden R-Squared measure: ```r install.packages("pscl") library(pscl) pR2(model) llh llhNull G2 McFadden r2ML r2CU -14.2949557 -36.7395040 44.8890966 0.6109105 0.2586338 0.6678078 ``` This yields a McFadden score of 0.611, which might be comparable to a linear regression's R-Squared metric. ```r # Run on test data: test_run<-test %>% select(-class_winner) fitted.results <- predict(model,test_run, type='response') fitted.results <- ifelse(fitted.results > 0.5,1,0) misClasificError <- mean(fitted.results != test$class_winner) misClasificError print(paste('Accuracy',1-misClasificError)) #[1] "Accuracy 0.912280701754386" #CrossTable: CrossTable(fitted.results, test$class_winner, prop.chisq = F, prop.t = F, dnn = c("Predicted", "Actual")) ``` While we get an verism of 91%, this result is misleading. The model couldn't find who is going to win. Only who is not to win, which isn't really our problem at this stage, but one reason we get such upper verism score.  ```r ctrl <- trainControl(method = "repeatedcv", number = 10, savePredictions = TRUE) mod_fit <- train(class_winner ~., data=win_r, method="glm", family="binomial", trControl = ctrl, tuneLength = 5) pred = predict(mod_fit, newdata=test) confusionMatrix(data=pred, test$class_winner) ``` We can personize the verism result with K-Fold navigate validation, a inside model performance metric in machine learning. We wield one of the most worldwide variation of navigate validation, the 10-fold cross-validation and exhibit the result via a ravages matrix. Now we get an plane higher verism score of 95 percent. Still, the model couldn't find the winners.  ## Predicting winning a medal: The data only covers two years of the games. This makes it nonflexible for a model like this to spot winners. What we could be doing instead is to tune lanugo our standards, and only squint for the lucky three winners who make it onto a podium. For that, we need to summate an uneaten column, and add a "1", for all skaters who made it among the top three, and "0" for the ones that didn't. To test our new model, we will run it on the most recent game in New Jersey, without cleaning the training data. ```r set.seed(10) win_r <- sample_n(test <- win[c(1:68, 77:207),], 199) train <- win_r test <- win[69:76,] ##New-Jersey-2016 model <- glm(top_3_outcome ~.,family=binomial(link='logit'),data=train) test_run<-test %>% select(-top_3_outcome) fitted.results <- predict(model,test_run, type='response') fitted.results <- ifelse(fitted.results > 0.5,1,0) misClasificError <- mean(fitted.results != test$top_3_outcome) print(paste('Accuracy',1-misClasificError)) #[1] "Accuracy 0.75" #CrossTable: CrossTable(fitted.results, test$top_3_outcome, prop.chisq = F, prop.t = F, dnn = c("Predicted", "Actual")) ```  This model performs better. Except of 2 miss-classified instances, we got 2 out of 3 podium winners right. While it did well on the two winners - Nyjah Huston (1st), Chris Joslin (2nd), with 90% and 80% probability respectively - the model could not icon out the third place, that was labelled as "other" in our training data. Tommy Fynn was not included in the practice when I labelling the rank_skater post (skaters that will play Sunday's finals were labelled in the data). As good practice requires, we will squint at is ROC lines to produce a visual representation for the AUC, a performance measurements for a binary classifier. ```r install.packages("ROCR") library(ROCR) fitted.results <- predict(model,test_run, type='response') fitted_for_ROCR <- prediction(fitted.results, test$top_3_outcome) performance_ROCR <- performance(pr, measure = "tpr", x.measure = "fpr") # plot: plot(prf) AUC <- performance(fitted.results, measure = "auc") AUC <- auc@y.values[[1]] #[1] 0.7333333 ```  An AUC of 0.73 is not entirely pleasing, but it's a start. We could now squint for which score each skater on Sunday would need to proceeds for decent win probability. For this, we could build a test-set with the skater names and run scores ranging from 1 to 10 (we once know that skater and Run_HST are powerful predictors for the podium medals). ```r ### probabilities for highest scores: scores <- seq(1, 10, 0.1) skaters <- c("NyjahHuston", "ShaneONeill", "PaulRodriguez", "LuanOliveira", "TomAsta", "RyanDecenzo", "CodyMcEntire", "ChrisJoslin") df_skate <- NULL for (skater in 1:length(skaters)) { for (s in 1:length(scores)) { df_skate <- rbind(df_skate, cbind(as.data.frame(scores[s]), as.data.frame(skaters[skater]))) } } names(df_skate)[1] <- "Run_HST" names(df_skate)[2] <- "rank_skater" fitted.results <- predict(model,df_skate, type='response') # with Run_HST and rank_skater as input variables ggplot(props, aes(Run_HST, fitted.results, group = rank_skater, col = rank_skater)) + geom_line() + theme_minimal() ```  Win probabilities orchestration for each skater from their highest run scores. # Wrapping up As we have seen, Nyjah Huston, Shane O'Neill and Paul Rodriguez do have weightier chances to make it on the podium. In which combination is unclear, but we will find out shortly. We have moreover learned how to wield a logistic regression on skateboarding, and how to compare the results wideness the various types of models we build. Two increasingly models have been built. A neural network model and a random forrest model, both which didn't perform as well as the logistic regression. -->Ben Heubltechjournalism@gmail.comThe Level of education plays a significant role in how we segregate a partner. But how does the level of education of our parents relate to how Americans marry? It turns out that the gap of length of education between spouse and parents used to shrink and now seemed to have stopped remoter converge.Moreoverthe wringer shows that mothers used to shepherd school longer than fathers in the past, but the reverse is true today.The Good, the Bad and the Ugly: The truth well-nigh the sexuality sultana model industry…2016-12-05T00:00:00+00:002016-12-05T00:00:00+00:00https://benheubl.github.io/data%20analysis/models_article<p><strong>An investigation into the global state of the sexuality model industry triggered an wringer of 9,687 sexuality model profiles and 1,101 modeling agencies. The search for vestige revealed that 74% of models are underweight and that the industry is largely misrepresented. It showed the importance for a larger proportion of slim-size models in big agencies to proceeds a higher financial credit scoring. It could expose vestige that those younger sexuality models in the data are at higher risk to be severely underweight and thus risk to develop weight-related health problems, increasingly than their older counterparts. An wringer of modeling agency-businesses uncovered which of those are the biggest industry pollutants of employing most underweight young models. For the fun of it, the data was used to estimate the world’s most lulu malleate model country population, via an wonk tideway (hint - a place men might shout: “Bonza, mate, she’s a ripper”).</strong></p> <p><img src="/images/models_article/head_6.png" alt="alt text" /></p> <p><em>Image: <a href="http://rebloggy.com/post/lol-death-hair-cute-adorable-fashion-skinny-thin-vogue-model-skull-skeleton-maga/23034409677">Media.tumblr.com</a></em></p> <p>Only who has what it takes - that is, a very particular soul image - will have the opportunity to wilt a malleate model. Requirements are tough. At least that’s what I’d unsupportable when I started researching this story. Modeling blog posts, such as <a href="http://modelingwisdom.com/height-age-and-measurement-requirements-of-modeling">this</a> one, authored by Jonah Levi Taylor don’t hibernate the fact that women ought to meet those tough soul requirements surpassing plane playing with the idea of going into modeling.</p> <h2 id="mom-google-says-im-not-tall-enough--my-waist-would-be-too-large-for-fashion-modeling"><em>“Mom, Google says I’m not tall unbearable & my waist would be too large for malleate modeling”</em></h2> <p>But do those numbers add up? How virtuously are those measurement assumptions stuff met by professional models? Of course, there are variegated categories. From the noise in the malleate media, I unsupportable that the largest part is represented by upper malleate modeling, itemize modeling, by lingerie and bikini modeling. I was proven wrong. It triggered a data-driven investigation into the sexuality malleate world.</p> <p><img src="/images/models_article/compare_2.png" alt="alt text" /></p> <p>To my unconfined surprise, it uncovered much increasingly than I initially had hoped for. My deep-dive into the data from <a href="http://www.fashionmodeldirectory.com/">Fashionmodeldirectory.com (FMD)</a> - a website that hosts sexuality modeling information, their agencies, soul measurements and personal information - tells an invaluable story of the current state of the global sultana sexuality modeling industry. Let me take you on a journey.</p> <h1 id="about-80-of-female-professional-models-are-simply-forgotten">About 80% of sexuality professional models are simply forgotten</h1> <p>Only well-nigh 22%, or 2,126 models from a total of 9,696 sexuality models could comply with a malleate blogger’s seemingly wrong-headed rules for soul measurements (including all variations of measurements for high-fashion, itemize modeling, lingerie and bikini modeling). If you are either, a young lady or sultana woman, playing with the idea of going into modeling, it is prudent NOT to listen to Jonah Levi Taylor’s suggestions for cut-off points, or alike. Those restrictions exclude the majority of the modeling market.</p> <p>In a post on modelingwisdom.com, next to other unimpressive posts that siphon headlines such as “How to get your Baby into Modeling” or “Why Can’t Models Be Short?”, the blogger claims that high-fashion models (or haute couture models) must be between 5’9″- 6″ tall, must have a thorax of between 32″-36″, a waist between 22″-26″, and hips of between 33″-35″. If tested on up-to-date data for sexuality FMD modeling profiles (status: November 2016), we learn that only well-nigh 14% of professional and successful models could comply with those “expert rules”.</p> <p><img src="/images/models_article/chart_restictions_2.png" alt="alt text" /> <em>Chart: Only well-nigh 14% of models could comply with blogger’s claims on model’s soul measurement requirements on upper couture fashion, source: FMD</em></p> <p>Of undertow - quite reasonably - one can oppose that the model industry does not merely consist of upper malleate models. If we include catalogue models too, considering Taylor’s recommended height measurements of between 5’8″ and 5’11”, a thorax of 32″-35″, hips of 33″-35″, and waist of 22″-26″ (slightly less restrictive compared to upper malleate models), only well-nigh 20% of professional models pass.</p> <p>There are other areas. For Lingerie and bikini models, it’s a similar story. Only well-nigh 22% of models meet those standards of lingerie modeling. It needs a height 5’7″-6′, thorax 32″-35″, waist 22″-26″, and hips 33″-35″. We are recommended to add a bit increasingly space onto model’s bust, when hunting for bikini models. A reason is not given. For this, we add flipside 1-2 inches. For those cut-offs, we only can grasp 5-16%.</p> <p>If we considered the abover all-together - this is, all possible variations from the modeling types from whilom - there is only well-nigh 22% that makes up the sultana sexuality malleate market, listed on FMD. The tragedian hereby suggests that nearly 80% are defended to the rest, including fields like fitness modeling, glamor, and plus-size modeling that do not require such specific measurements. Can you smell the ignorance?</p> <p>Similar cut-off claims have been made. Similar results were found on those claims (for instance from <a href="http://www.modelmanagement.com/modeling-advice/can-i-be-a-model/">modelmanagement.com</a>). It includes plus size modeling and reports a minimum height of 172cm, while the data shows a smaller height is well possible. Taylor’s blog post or those claims by Modelmanagement.com siphon serious weight for those young girls, searching for translating online. They towards on the first page of search engines, and misrepresent how diverse the industry really is. For my own online search, both towards to be the top two sources found when searching for <em>“What measurements do i need to be a model”</em> on Google.</p> <p>It is unscratched to say that those claims can’t be taken seriously if 8 out of 10 models are stuff ignored. Today’s modeling industry with the rise of the web seeks a much wider <a href="http://www.elleuk.com/fashion/trends/longform/a31200/diversity-in-fashion/">variaty of models</a>. Whether thin, small, tall, woebegone or white, the concept of diversity is in vogue, increasingly than ever. Today’s diverse demand is <em>in</em>, and those soul restrictions should’t really be of any reliable reference anymore.</p> <h1 id="does-the-model-industry-need-a-new-way-to-control-for-models-health">Does the model industry need a new way to tenancy for model’s health?</h1> <p>Let’s talk well-nigh health. It has now been nearly one year since the French government decided to <a href="http://www.bbc.co.uk/news/world-europe-35130792">pass legislation</a> that makes malleate models provide a medical note to prove that they are healthy. It is similar to what other countries have once implemented - such as Italy, Spain and Israel. French legislators reasoned the transpiration with upper numbers of <a href="http://www.insidermonkey.com/blog/11-countries-with-the-highest-rates-of-eating-disorders-in-the-world-353060/">eating disorders and cases of anorexia</a>. <a href="http://www.france24.com/en/20080416-france-cracks-down-anorexia-france-health">Anorexia</a> affects between 30,000 – 40,000 people in France, 90% of whom are women (stats from 2008). It seems I’m in the right spot to dig deeper into the data.</p> <p><img src="/images/models_article/head.png" alt="alt text" /></p> <p>The recent <a href="https://www.victoriassecret.com/fashion-show">Victoria’s Secret Show 2016</a> in Paris in December came in real handy, and offered an opportunity to review on those legislative changes since its introduction. So far, nothing seems to have reverted much. Victoria’s Secret (VS) could spark some hope for healthier looking models, on their own. The visitor belongs to a group of global and influential organizations, that is in the unique position to help transpiration the perception, and to show what good looking, healthy and fit malleate models could squint like.</p> <p>The company’s oversight on model’s health and fitness impressed many. The retail giant and its models worked on their fitness and health branding together, over the last years. The effort seemed to have <a href="http://www.vogue.co.uk/gallery/victorias-secret-angels-exercise-tips-and-secrets">paid off</a>. Victoria’s Secret’s vein on contracting healthy and fit models seem to siphon real weight, and VS influence is undeniable. 6.65 million people watched the show on TV this year - an increase from last year’s 6.60 million.</p> <p><img src="/images/models_article/rn_2.png" alt="alt text" /></p> <p><a href="http://www.bbc.com/news/uk-england-34966116">Rosie Nelson</a>, a model herself, who started <a href="https://www.change.org/p/cj-dinenage-create-a-law-to-protect-models-from-getting-dangerously-skinny-lfw-modelslaw">petitioning</a> the UK Government to introduce legislation to stop the use of models who are unhealthily thin, pushes for the introduction of health checks. As far as she is aware, those legislations in France haven’t been put into full whoopee yet. She did a catwalk show at ParisMalleateWeek in September and encountered girls who she would consider underweight and not at the peak of their physical health. There was no mention of health certificates or physical health medical notes whilst she was there, she says. In her opinion, it is definitely one strong way forward for the industry, if it is managed and controlled in a responsible way.</p> <h2 id="clean-figures-on-underweight">Clean figures on underweight</h2> <p>Despite leaving off a uncontrived judgement of who is unhealthy and who isn’t, by classifying underweight using waist and model’s height, 74% of models or 7,186 women, would fall in a hair-trigger range of a waist-height ratio unelevated 0.35.</p> <p>This can be <a href="http://www.shapefit.com/calculators/waist-to-height-ratio-calculator.html">classified</a> as a state of underweight, but one single well-spoken and strong guide couldn’t be found (<em>It makes sense since everyone has a slightly variegated soul shape. We will use the waist-height measure anyway since it’s the weightier we have as an underweight indication from the FMD data. 0.35 shall hereby serve us as cut-off guide value</em>). The waist-height ratio is a measurement of the waist circumference divided by height (both in cm).</p> <p><img src="/images/models_article/below_0_35_2.png" alt="alt text" /> <em>Chart: 74% of models in the sample have a lower waist-height ratio than 0.35, classifiable as underweight. source: FMD</em></p> <p>Health professionals report that for women who are severely underweight the risk is higher to suffer from amenorrhea (absence of menstruation), infertility and possible complications during pregnancy. It can moreover rationalization anemia and hair loss.Stuffunderweight is an established risk factor for developing osteoporosis, plane for young people. One typical measure is the BMI (the underweight definition usually refers to people with a soul mass alphabetize (BMI) of under 18.5 or a weight 15% to 20% unelevated that normal for their age and height group). A person may be underweight due to genetics, metabolism, drug use, lack of food, or illness - or, in some cases, due to soul shape requirements set out by their modeling job.</p> <p>Female Russian malleate models stood out with the lowest reliable stereotype waist-height ratio, a victory which I could imagine no country would fancy wining. On average, those women were lying significantly unelevated the 0.35 cut-off point. British (English) models made it closest to this mark.</p> <p><img src="/images/models_article/dist_0_35_2.png" alt="alt text" /> <em>Chart: Distribution waist-height per country, source: FMD</em></p> <p>It is often unsupportable that the stereotype waist-height value among haute couture models is lower (lumpen designers think that their gown squint largest on skinny models).</p> <p>Let’s have a squint at those models, exclusively. A second density orchestration has been drawn up (‘thanks’ to Taylor suggestions).</p> <p>Now, Chinese women models have the lowest waist-height ratio while the Swedish are most modest, coming closest to 0.35. Models from Czech Republic, Lithuania, and Brazil reveal an interesting multimodal density distribution, indicated by two or increasingly of those funny humps.</p> <p>Mexican, Canadian and Spanish models have such multinomial policies too, but with increasingly than two humps.</p> <p><img src="/images/models_article/dist_0_35_fashion_3.png" alt="alt text" /> <em>Chart: Distribution waist-height of upper couture models, per country, source: FMD</em></p> <h2 id="current-model-squat-by-victorias-secret">Current model squat by Victoria’s Secret</h2> <p>Above, I named Victoria’s Secret as possible instigator and trendsetter for increasingly fit looking, increasingly healthy models. We can see the current <a href="https://www.victoriassecret.com/vsallaccess/angels">“Angel squad”</a> represented in the scatterplot, comparing their waist and height to the rest of the industry.</p> <p><img src="/images/models_article/compare_angels_3.png" alt="alt text" /> <em>Chart: Current squat of Victoria’s Secret models, and their waist-height measurements, source: FMD</em></p> <p>Josephine Skriver with a waist-height ratio of 0.31 is furthest yonder from the 0.35 waist-height ratio mark, making her the “thinnest” among the group. Martha Hunt with a ratio of 0.36 is closest to it, and didn’t plane classify as underweight, which is applaudable. Needless to say, everyone has a variegated soul shape, yet, all of those models have a somewhat healthy line.</p> <p>This is considering health and fitness of their models is top-priority, and VS is well in tenancy of. Although, the data suggests that the stereotype waist-height ratio of this year’s’ Victoria’s Secret Angel squad touches slightly unelevated the 0.35 mark, there are several significant differences, argues Iva Mirbach, Editor-In-Chief at FMD: “The workout and shaping plan by Victoria’s Secret could serve well as a perfect standard for the industry. Models are moreover forced to have a healthy diet”.</p> <p>Contracts Victoria’s Secret models sign are - funnily unbearable - secret. Nevertheless, the unstipulated theorizing is that models are required to shape-up their soul for a “healthy and muscular” figure, says Mirbach. (Angels should be 5ft 9in with a 24inch waist and no increasingly than 18 percent of soul fat). The training has consequences. Those requirements make those models waif significantly under the regular soul mass index, but models have a higher proportion of muscle mass, something that is usually a good indicator for a healthy person.</p> <p>Daniel Elliott, a specialist nurse at the department of feeding at theUnconfinedOrmond Street Children’s hospital in London says that low muscle mass is one of several important indicators to tell untied anorexia from healthy, thin bodylines (more sport and fitness would moreover increases the level of appetite, increasingly naturally, he tells me on the phone).</p> <p><img src="/images/models_article/VS_models.png" alt="alt text" /> <em>Image: Healthy Victoria’s Secret image via <a href="http://images.google.de/imgres?imgurl=https%3A%2F%2Fwww.fitazfk.com%2Fwp-content%2Fuploads%2F2016%2F05%2Flandscape-1447175108-angels-index.jpg&imgrefurl=https%3A%2F%2Fwww.fitazfk.com%2Ffive-victorias-secret-angels-diet-and-exercise-secrets%2F&h=490&w=980&tbnid=rVnrbwcZJMtk5M%3A&vet=1&docid=_bLcG10mBsx7QM&ei=PxJgWJvyN8uja5vpsOgF&tbm=isch&iact=rc&uact=3&dur=366&page=0&start=0&ndsp=20&ved=0ahUKEwjbjd_z_o_RAhXL0RoKHZs0DF0QMwgaKAAwAA&safe=strict&bih=667&biw=1440">FitazFK</a></em></p> <p>VS model’s muscular and healthy soul shape is increasingly sought without by various large sports and fitness brands. One example is wearable technology that includes products such as fitness watches, that are increasingly stuff marketed and branded under the fitness and health umbrella.Increasinglydemand of those sporty models could follow for mainstream malleate brands too, and reduce the risk that anorexic models will remain undetected and without help. Despite the opportunities, the <a href="http://www.hindustantimes.com/fashion-and-trends/muscular-and-hunky-is-out-male-fashion-models-are-choosing-to-be-thin-even-androgynous/story-ZGaijSLXQrsyPikSrDFvwO.html">opposite</a> seems to be happening for male modeling at the moment, where less muscular soul shapes are rhadamanthine higher in demand.</p> <h1 id="measuring-attractiveness">Measuring attractiveness</h1> <p>To get a feeling of how <em>“attractive”</em> models are within the FMD data, I conducted a little experiment, that was guided by results from a scientific <a href="http://www.ehbonline.org/article/S1090-5138(02)00121-6/abstract">study</a> by Streeter and McBurney from the department of Psychology, at the University of Pittsburgh.</p> <p>The researchers tested the perception of sexiness of women, perceived by men. Hereby, the waist–hip ratio played an important role.</p> <p><img src="/images/models_article/attr_head_3.png" alt="alt text" /></p> <p>The study could personize that waist–hip ratio (WHR) in women can be used as a suitable indicator for men in the sample group to judge sexiness equal to signals of health, youth, and fertility in potential mates. An evolutionary model could then predict that humans should prefer those honest signals.</p> <p>The interesting bit is that an “optimum value” was determined. 0.7 waist-hip ratio was most preferred (which is in line with results from older studies). We can compare this to the FMD data points and get a detailed worth on mean-value deviations from 0.7, for waist-hip ratios wideness model’s countries of origins.</p> <p><img src="/images/models_article/attractiveness_2.png" alt="alt text" /> <em>Chart:Midpointwaist-hip ratio values of model’s origins, and deviation from optimum waist-hip ratio of 0.7, source: FMD</em></p> <p>The deviations from the “optimum” is largest for Belarusians, which has a midpoint waist-hip value of 0.676 (72 women in the sample). 0.702 is the waist-hip ratio for models from New Zealand, which reached the highest stereotype value (67 women in the sample). Most accurately, that is, - equal to the result, most “attractive” - are models from Ireland (31 women) and models from Australia (357 women), who do deviate the least.</p> <p>Remember those Victoria’s Secret models, we discussed earlier? Their stereotype waist-hip ratio is 0.69. The squat only missed the 0.7 mark by a hair’s breadth.</p> <p>If we unravel it lanugo and compare the most represented countries in terms of their density distributions within the FMD sample, we learn that Slovakians are much much remoter yonder from the optimum than models from Australia (which scrutinizingly perfectly hit the 0.7), Canada, America, Britain. All of those four western countries lean towards the right of the 0.7 mark. Whether this is a trend that might be influenced by a increasingly diverse modeling sector, I can’t tell (but do leave a scuttlebutt if you think you know more).</p> <p><img src="/images/models_article/dist_0_70_final.png" alt="alt text" /> <em>blue line = country’s midpoint waist-hip ratio, red line = waist-hip ratio of 0.7</em> <em>Chart: Density distributions of midpoint waist-hip ratio values of model’s origins, source: FMD</em></p> <p>If we perform a similar task for high-fashion models, Russian women are furthest yonder from the sweet spot of 0.7 waist-to-hip ratio.</p> <p><img src="/images/models_article/dist_0_70_high_fashion.gif" alt="alt text" /> <em>blue line = country’s midpoint waist-hip ratio, red line = waist-hip ratio of 0.7</em> <em>Chart: Density distributions of midpoint waist-hip ratio values of upper malleate model’s origins, source: FMD</em></p> <h1 id="age">Age</h1> <p>Eating disorders can be an intense problem for teenagers and people in their early twenties. Recently, we could witness some - yet scattered - responses from the industry. For instance, there was Anna Wintour - British-American journalist and editor-in-chief of Vogue since 1988 - who made it a rule to never photograph girls under 16 years old or with a known eating disorder. This is applaudable. Data on hospitalizations caused by eating disorders fit into the picture. It can justify Anna’s take on it, and exposes the indsutry’s own illness. A upper proportion of underweight models is found among younger models.</p> <p><img src="/images/models_article/eating_disorders_canda2.png" alt="alt text" /></p> <p>For virtually every third model in the FMD data, an age could be calculated. Although, the FMD data presented mainly profiles on sultana models (18+), the highest proportions for models with a low waist-height ratio - < 0.33 or < 0.32 - was found for 18 to 22. This is in line with the orchestration on hospitalizations caused by eating disorders, above.</p> <p><img src="/images/models_article/young_2.png" alt="alt text" /></p> <p>Chart: Age groups and proportions of models with a waist-height ratio smaller than 0.32 and 0.33, classified here as severely underweight, source: FMD</p> <h1 id="a-golden-age-for-older-models">A golden age for older models?</h1> <p>High malleate models in the FMD data, have a median age of 29, which is higher than the median age of Victoria’s Secret Angels models of 26.5. From the wits of model organ owner Katarzyna Sawicka, I was told well-nigh a trend for a demand of older models.</p> <p>Sawicka owns Gaga Models, a smaller Polish model organ in Poznań, a municipality on the Warta River in western Poland. She says that only a few years ago, she wouldn’t have well-set to take on girls within the age between 23 or 25.Whenthen, those were too old.</p> <p><img src="/images/models_article/young_image.png" alt="alt text" /> <em>Image: “The media proclaimed ‘outrage’ over the young Israeli on the catwalk—but fashion’s obsession with youth is long-enduring”, source: <a href="http://www.thedailybeast.com/articles/2015/07/28/is-sofia-mechetner-14-too-young-to-model-for-christian-dior.html">thedailybeast.com</a></em></p> <p>It’s a good thing that agencies scout for older women models these days. An approximately 2–4% of the young sultana sexuality population are unsupportable to suffer from full syndrome eating disorders. In the time between 16–20 years, the onset appears to be highest.</p> <p>In addition, the wringer of the measurements from thos age-groups revealed that sexuality models of 18 or under had one of the lowest midpoint value in waist measurements. Yet, those women were among the tallest.</p> <p>The longer agencies can wait to lay their unprepossessed fingers on those younger models, the better.</p> <p><img src="/images/models_article/young_agencies_4.png" alt="alt text" /> <em>Chart: Agencies that rent the youngest, and most underweight models: Ten other model agencies that stood out, who decided to contract comparably young and underweight models are shown and annotated within the scatterplot. 3.4 representing agencies (FMD data) has each model on average. So, it could be possible that agencies share accounts. Source: FMD</em></p> <p>Sawicka’s agency, <a href="http://gaga.pl/en,contact">Gaga Models</a>, showed up in the data with one of the lowest stereotype scores for both, age of models and waist-height ratio (chart), but only rumored for a small sample. Other similar agencies include Supermodels Model Management (16 models) or Chantale Nadeau Model Placement (12 models), have a slightly larger sample and could be tabbed out for that. Yet, those agencies dont worth for the numbers that influence an unshortened industry.</p> <p>Let’s take a squint at those larger agencies.</p> <h1 id="large-in-size-with-a-high-proportion-of-underweight-models">Large in size with a upper proportion of underweight models</h1> <p>One hundred modeling agencies with the largest proportion of dress size models 0-3 were filtered from the data to compare the ratio of 0-3 size models with the merchantry success rating of those agencies. All of those have at least 100 models or increasingly on the payroll.</p> <p>The <a href="http://www.mars.im/analytics/globalmarket/">financial scoring</a> finance for the global market share and influence (a measure provided by the credit and reputation risk rating system, IFDAQ) of modeling agencies. A positive correlation could be found, and ways a relationship might exist of a large proportion of thin models and agency’s financial scoring.</p> <p>Sadly, it should be the other ways around. Agencies shouldn’t be rewarded for their effort to scout for the skinniest.</p> <p><img src="/images/models_article/ratio_vs_rating_5.png" alt="alt text" /> <em>Chart: Correlation of overall size and ratio of 0-3 dress size models, source: Credit and Reputation Risk Rating System, IFDAQ</em></p> <p>When purely looking at the agencies proportion of 0-3 size models, the merchantry of <em>The Society Model Management</em> organ stands out by far with 66 0-3 dress size models out of 109. It finance for the largest proportion among the list of agencies. Storm Models London sticks out as the largest modeling organ in the data. It has 1,266 models in their books, and wins moreover the competition for the organ with the largest headcount of 0-3 dress size sexuality models (of 239). It moreover enjoys the highest financial rating score of 16.16.</p> <p>One prominent public icon and his organ made it among those 100 accounts: Future US. president Donald Trump. The <a href="http://www.trumpmodels.com/">Trump model agency</a>, with 21% (or 41 out of 196) of 0-3 dress size models, made it onto rank 64.</p> <p>9 types of the <em>Elite Model Management</em> organ have been spotted, each responsible for variegated municipality or country location. Elite Model Management for Milan, Paris and Barcelona were among the top 10 with the largest proportion of 0-3 dress size models (each with virtually 45% of thin type models on their payroll). IMG Models, flipside visitor that has multiple offices for various city/country locations, rumored for five datapoints, whereby two of them (Milan and Sydney) rank among the top ten.</p> <p><img src="/images/models_article/worst_agencies_3.png" alt="alt text" /> <em>Chart: 100 agencies with the largest proportion of 0-3 dress size models and their ratios of such, source: FMD</em></p> <p>Of those agencies listed with a unravelment of a subsidiary municipality office (e.g. Elite Model Management <em>Paris</em>) 14 were based in New York, 11 in Paris and Milan, and 6 in London.</p> <h1 id="lets-improve">Let’s improve</h1> <p><a href="http://images.google.de/imgres?imgurl=https%3A%2F%2Fi-d-images.vice.com%2Fimages%2Farticles%2Fmeta%2F2015%2F11%2F23%2Fthe-bmi-debate-how-do-you-measure-the-health-of-models-1448283073.jpg%3Fcrop%3D0.99415204678363xw%3A1xh%3Bcenter%2Ctop%26resize%3D1200%3A*%26output-format%3Dimage%2Fjpeg%26output-quality%3D75&imgrefurl=https%3A%2F%2Fi-d.vice.com%2Fen_gb%2Farticle%2Fthe-bmi-debate-how-do-you-measure-the-health-of-models&h=675&w=1200&tbnid=MSSabi4lLgeqaM%3A&vet=1&docid=FaozkCM-J6QjoM&ei=WmhhWM2QHoTda7fNoogJ&tbm=isch&iact=rc&uact=3&dur=1025&page=1&start=18&ndsp=28&ved=0ahUKEwjNpbuUxZLRAhWE7hoKHbemCJEQMwhNKCswKw&safe=strict&bih=667&biw=1440">Rosie Nelson</a> wrote in an email to me. She thinks that health should come first: “I think that modeling agencies would goody hugely from focusing increasingly on their model’s health rather than their size or measurements. There have been myriad times where I have been rejected from a job just considering my hips were an inch too big. The focus should be on whether a model is happy and healthy, in their mind and body, rather than the size of their jeans. “</p> <p>To reduce model’s own responsibility - and to increase agencies investment in their health -, to fight <a href="http://smallbusiness.chron.com/pressures-modeling-industry-38285.html">anorexia and eating disorders</a>, let me make some vital suggestions:</p> <ul> <li><em>Agencies must take increasingly responsibilty</em></li> <li><em>A simple health trammels without management and enforcement, like France introduced it, makes little sense. Those legislations need proper oversight.</em></li> <li><em>Models shouldn’t be told by their organ to lose weight in the first place (why is this legal), expressly sexuality model once unelevated their 0.35 waist-height ratio.</em></li> <li><em>Legislation and health authorities should have ways to police and worldly-wise to prosecute those agencies that would violate those rules.</em></li> <li><em>There should be legal responsibilities by agencies, in specimen things go wrong. For this, legislators should require to provide a minimum level of support. It simply shouldn’t be left to those models alone.</em></li> <li><em>Modeling agencies should be required to report on model’s health, similar to their financial reporting, to the government and health authorities. Such data points are invaluable to research, which can help to reduce eating disorders and anorexia within the industry.</em></li> </ul> <p>Iva Mirbach from FMD wouldn’t want to requirement that catwalk models are less healthy per se. The secret is the manner of how VS models stay in shape: “VS models are forced to have a healthy nutrition and regular sport to stay in shape as this is a part of the contract of Victoria’s Secret, whereas other non-VS-models can decide by themselves how they reach their goals as malleate models”. Since the group of VS models is moreover kept intentionally small (currently 14), largest oversight can be provided.</p> <p>At last, modeling agencies might learn a unconfined deal from Victoria’s Secret’s approach*.</p> <p><img src="/images/models_article/VS_CW_3.png" alt="alt text" /> <em>Chart: Victoria’s Secret vs. catwalk models: Catwalk malleate only represents a fraction of the sexuality modeling industry, as we could see earlier. The loftiness walked on catwalks by the Victoria’s Secret Angel squat is only a tenth of what catwalk models have on their record. This shows a comparison of a sample of experienced and top-ranked catwalk models with the current set of VS models (two angels, Behati Prinsloo and Candice Swanepoel, are missing). Both groups, among the top ranked models among their industry, can be cleanly separated (blue, red). VS Model’s score higher on their malleate media impact than the set of successful catwalk models. Source: FMD</em></p> <p><img src="/images/models_article/head3.png" alt="alt text" /></p> <p><em>Image: By Helmut NewtonUpper& Mighty Shoot, American Vogue, 1995: “Shoes: Pleasure and Pain” at Victoria and Albert Museum, London (2015)</em></p> <p>*Despite the fact that VS is unmistakably not a modeling agency, it’s a brand, a retailer.</p>Ben Heubltechjournalism@gmail.comAn investigation into the global state of the sexuality model industry triggered an wringer of 9,687 sexuality model profiles and 1,101 modeling agencies. The search for vestige revealed that 74% of models are underweight and that the industry is largely misrepresented. It showed the importance for a larger proportion of slim-size models in big agencies to proceeds a higher financial credit scoring. It could expose vestige that those younger sexuality models in the data are at higher risk to be severely underweight and thus risk to develop weight-related health problems, increasingly than their older counterparts. An wringer of modeling agency-businesses uncovered which of those are the biggest industry pollutants of employing most underweight young models. For the fun of it, the data was used to estimate the world’s most lulu malleate model country population, via an wonk tideway (hint - a place men might shout: “Bonza, mate, she’s a ripper”).How to wield squatter recognition API technology to data journalism with R and python2016-10-20T00:00:00+00:002016-10-20T00:00:00+00:00https://benheubl.github.io/data%20analysis/fr<p><strong>The Microsoft Emotion API is based on state of the art research from Microsoft Research in computer vision and is based on a Deep Convolutional Neural Network model trained to classify the facial expressions of people in videos and images. This is an struggle to explain how to wield the API for data-driven reporting.</strong></p> <p><img src="/images/face/face4.png" alt="alt text" /></p> <p>Let’s be honest, the last and final debate was depressing. The negativity, the personal allegations, and Trump’s Belzebub-like facial expressions made it difficult to stay up to 3:30am and watch this gainsay with my American wife, which resembled an old feisty couple tropical to divorce. However, the debate was a gold mine for computer assisted reporting. One of the APIs I recently stumbled wideness when talking to the research lab from Microsoft is a neat emotion video API. It is a facial recognition software API based on a deep convolutional Neural Network model trained to classify the facial expressions of people in videos and images.</p> <p>The team at Microsoft promises that users receive a conviction score wideness the “universal emotions” based on the associations between facial expressions and emotions identified from years of psychology literature.Equalto Anna Roth at Microsoft, the model is trained on tens of thousands of images labeled with the universal expressions.</p> <h1 id="the-debates-are-a-goldmine-for-emotion-research">The Debates are a goldmine for emotion research</h1> <p>One vendible talked well-nigh the weightier way to wits the extremes of this years presidential debate rally, which is to turn off the sound. The last three presidential debates, besides stuff difficult to watch, offered me a new unique opportunities to wield facial recognition technology to journalism. We will take a few clips and perform a simple wringer on facial expressions in the context of spoken words. The wringer served moreover as a bases for an <a href="http://www.economist.com/blogs/graphicdetail/2016/10/daily-chart-12">article</a> we ran at the Economist Newspaper.</p> <h1 id="python-setup">Python setup:</h1> <p>We will run the API on a video prune for the third debate, and use a sample of the last 5 minutes for this analysis. It serves us as a sample, and we hopefully will get a good taste for the two candidate’s facial expressions. You can set up a self-ruling API key <a href="https://www.microsoft.com/cognitive-services/en-us/emotion-api">here</a>.</p> <div class="language-python highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="kn">import</span> <span class="nn">httplib</span> <span class="kn">import</span> <span class="nn">urllib</span> <span class="kn">import</span> <span class="nn">base64</span> <span class="kn">import</span> <span class="nn">json</span> <span class="kn">import</span> <span class="nn">pandas</span> <span class="k">as</span> <span class="n">pd</span> <span class="kn">import</span> <span class="nn">numpy</span> <span class="k">as</span> <span class="n">np</span> <span class="kn">import</span> <span class="nn">requests</span> <span class="c"># you have to sign up for an API key, which has some allowances.Trammelsthe API documentation for remoter details:</span> <span class="n">_url</span> <span class="o">=</span> <span class="s">'https://api.projectoxford.ai/emotion/v1.0/recognizeInVideo'</span> <span class="n">_key</span> <span class="o">=</span> <span class="s">'insert your key here'</span> <span class="c">#Here you have to paste your primary key</span> <span class="n">_maxNumRetries</span> <span class="o">=</span> <span class="mi">10</span> </code></pre></div></div> <p>The Python 2 setup requires us to load in a few libraries. Next we are calling the response for the video url we want to receive the wringer for.</p> <div class="language-python highlighter-rouge"><div class="highlight"><pre class="highlight"><code> <span class="c"># URL direction: I hosted this on my domain</span> <span class="n">urlVideo</span> <span class="o">=</span> <span class="s">'http://datacandy.co.uk/blog2.mp4'</span> <span class="c"># Computer Vision parameters</span> <span class="n">paramsPost</span> <span class="o">=</span> <span class="p">{</span> <span class="s">'outputStyle'</span> <span class="p">:</span> <span class="s">'perFrame'</span><span class="p">}</span> <span class="n">headersPost</span> <span class="o">=</span> <span class="nb">dict</span><span class="p">()</span> <span class="n">headersPost</span><span class="p">[</span><span class="s">'Ocp-Apim-Subscription-Key'</span><span class="p">]</span> <span class="o">=</span> <span class="n">_key</span> <span class="n">headersPost</span><span class="p">[</span><span class="s">'Content-Type'</span><span class="p">]</span> <span class="o">=</span> <span class="s">'application/json'</span> <span class="n">jsonPost</span> <span class="o">=</span> <span class="p">{</span> <span class="s">'url'</span><span class="p">:</span> <span class="n">urlVideo</span> <span class="p">}</span> <span class="n">responsePost</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">request</span><span class="p">(</span> <span class="s">'post'</span><span class="p">,</span> <span class="n">_url</span><span class="p">,</span> <span class="n">json</span> <span class="o">=</span> <span class="n">jsonPost</span><span class="p">,</span> <span class="n">data</span> <span class="o">=</span> <span class="bp">None</span><span class="p">,</span> <span class="n">headers</span> <span class="o">=</span> <span class="n">headersPost</span><span class="p">,</span> <span class="n">params</span> <span class="o">=</span> <span class="n">paramsPost</span> <span class="p">)</span> <span class="k">if</span> <span class="n">responsePost</span><span class="o">.</span><span class="n">status_code</span> <span class="o">==</span> <span class="mi">202</span><span class="p">:</span> <span class="c"># everything went well!</span> <span class="n">videoIDLocation</span> <span class="o">=</span> <span class="n">responsePost</span><span class="o">.</span><span class="n">headers</span><span class="p">[</span><span class="s">'Operation-Location'</span><span class="p">]</span> <span class="k">print</span> <span class="n">videoIDLocation</span> </code></pre></div></div> <p>Next we harvest the response, without flipside cup of coffee (we need to wait a bit for the response).</p> <div class="language-python highlighter-rouge"><div class="highlight"><pre class="highlight"><code> <span class="c">## Wait a bit, it's processing</span> <span class="n">headersGet</span> <span class="o">=</span> <span class="nb">dict</span><span class="p">()</span> <span class="n">headersGet</span><span class="p">[</span><span class="s">'Ocp-Apim-Subscription-Key'</span><span class="p">]</span> <span class="o">=</span> <span class="n">_key</span> <span class="n">jsonGet</span> <span class="o">=</span> <span class="p">{}</span> <span class="n">paramsGet</span> <span class="o">=</span> <span class="n">urllib</span><span class="o">.</span><span class="n">urlencode</span><span class="p">({})</span> <span class="n">getResponse</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">request</span><span class="p">(</span> <span class="s">'get'</span><span class="p">,</span> <span class="n">videoIDLocation</span><span class="p">,</span> <span class="n">json</span> <span class="o">=</span> <span class="n">jsonGet</span><span class="p">,</span>\ <span class="n">data</span> <span class="o">=</span> <span class="bp">None</span><span class="p">,</span> <span class="n">headers</span> <span class="o">=</span> <span class="n">headersGet</span><span class="p">,</span> <span class="n">params</span> <span class="o">=</span> <span class="n">paramsGet</span> <span class="p">)</span> <span class="n">rawData</span> <span class="o">=</span> <span class="n">json</span><span class="o">.</span><span class="n">loads</span><span class="p">(</span><span class="n">json</span><span class="o">.</span><span class="n">loads</span><span class="p">(</span><span class="n">getResponse</span><span class="o">.</span><span class="n">text</span><span class="p">)[</span><span class="s">'processingResult'</span><span class="p">])</span> <span class="n">timeScale</span> <span class="o">=</span> <span class="n">rawData</span><span class="p">[</span><span class="s">'timescale'</span><span class="p">]</span> <span class="n">frameRate</span> <span class="o">=</span> <span class="n">rawData</span><span class="p">[</span><span class="s">'framerate'</span><span class="p">]</span> <span class="n">emotionPerFramePerFace</span> <span class="o">=</span> <span class="p">{}</span> <span class="n">currFrameNum</span> <span class="o">=</span> <span class="mi">0</span> <span class="k">for</span> <span class="n">currFragment</span> <span class="ow">in</span> <span class="n">rawData</span><span class="p">[</span><span class="s">'fragments'</span><span class="p">]:</span> <span class="k">for</span> <span class="n">currEvent</span> <span class="ow">in</span> <span class="n">currFragment</span><span class="p">[</span><span class="s">'events'</span><span class="p">]:</span> <span class="n">emotionPerFramePerFace</span><span class="p">[</span><span class="n">currFrameNum</span><span class="p">]</span> <span class="o">=</span> <span class="n">currEvent</span> <span class="n">currFrameNum</span> <span class="o">+=</span> <span class="mi">1</span> <span class="c"># Data collection</span> <span class="n">person1</span><span class="p">,</span> <span class="n">person2</span> <span class="o">=</span> <span class="p">[],</span> <span class="p">[]</span> <span class="k">for</span> <span class="n">frame_no</span><span class="p">,</span> <span class="n">v</span> <span class="ow">in</span> <span class="n">emotionPerFramePerFace</span><span class="o">.</span><span class="n">copy</span><span class="p">()</span><span class="o">.</span><span class="n">items</span><span class="p">():</span> <span class="k">for</span> <span class="n">i</span><span class="p">,</span> <span class="n">minidict</span> <span class="ow">in</span> <span class="nb">enumerate</span><span class="p">(</span><span class="n">v</span><span class="p">):</span> <span class="k">for</span> <span class="n">k</span><span class="p">,</span> <span class="n">v</span> <span class="ow">in</span> <span class="n">minidict</span><span class="p">[</span><span class="s">'scores'</span><span class="p">]</span><span class="o">.</span><span class="n">items</span><span class="p">():</span> <span class="n">minidict</span><span class="p">[</span><span class="n">k</span><span class="p">]</span> <span class="o">=</span> <span class="n">v</span> <span class="n">minidict</span><span class="p">[</span><span class="s">'frame'</span><span class="p">]</span> <span class="o">=</span> <span class="n">frame_no</span> <span class="k">if</span> <span class="n">i</span> <span class="o">==</span> <span class="mi">0</span><span class="p">:</span> <span class="n">person1</span><span class="o">.</span><span class="n">append</span><span class="p">(</span><span class="n">minidict</span><span class="p">)</span> <span class="k">else</span><span class="p">:</span> <span class="n">person2</span><span class="o">.</span><span class="n">append</span><span class="p">(</span><span class="n">minidict</span><span class="p">)</span> <span class="n">df1</span> <span class="o">=</span> <span class="n">pd</span><span class="o">.</span><span class="n">DataFrame</span><span class="p">(</span><span class="n">person1</span><span class="p">)</span> <span class="n">df2</span> <span class="o">=</span> <span class="n">pd</span><span class="o">.</span><span class="n">DataFrame</span><span class="p">(</span><span class="n">person2</span><span class="p">)</span> <span class="k">del</span> <span class="n">df1</span><span class="p">[</span><span class="s">'scores'</span><span class="p">]</span> <span class="k">del</span> <span class="n">df2</span><span class="p">[</span><span class="s">'scores'</span><span class="p">]</span> <span class="c"># Saving in pd data-frame format:</span> <span class="n">df1</span><span class="o">.</span><span class="n">to_csv</span><span class="p">(</span><span class="s">"/your/file/path/trump.csv"</span><span class="p">,</span> <span class="n">index</span><span class="o">=</span><span class="bp">False</span><span class="p">)</span> <span class="n">df2</span><span class="o">.</span><span class="n">to_csv</span><span class="p">(</span><span class="s">"/your/file/path/clinton.csv"</span><span class="p">,</span> <span class="n">index</span><span class="o">=</span><span class="bp">False</span><span class="p">)</span> </code></pre></div></div> <p>Finally, we need to save the data in a format that allows us to perform the wringer on the resulting data. We will do this via a CSV file, and protract our journey in R.</p> <h1 id="r-setup">R setup</h1> <p>Lets tickle out the good shit with the pursuit script:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1">########## Trump's face</span><span class="w"> </span><span class="n">blog_trump</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read.csv</span><span class="p">(</span><span class="s2">"/your/file/path/trump.csv"</span><span class="p">,</span><span class="w"> </span><span class="n">header</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">)</span><span class="w"> </span><span class="n">View</span><span class="p">(</span><span class="n">trump_g</span><span class="p">)</span><span class="w"> </span><span class="n">trump_g</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">blog_trump</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">gather</span><span class="p">(</span><span class="n">key</span><span class="p">,</span><span class="w"> </span><span class="n">value</span><span class="p">,</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="n">anger</span><span class="p">,</span><span class="w"> </span><span class="n">contempt</span><span class="p">,</span><span class="w"> </span><span class="n">disgust</span><span class="p">,</span><span class="w"> </span><span class="n">fear</span><span class="p">,</span><span class="w"> </span><span class="n">happiness</span><span class="p">,</span><span class="w"> </span><span class="n">neutral</span><span class="p">,</span><span class="w"> </span><span class="n">sadness</span><span class="p">,</span><span class="w"> </span><span class="n">surprise</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="o">!</span><span class="n">key</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"neutral"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">id</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="m">0</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">candidate</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Trump"</span><span class="p">)</span><span class="w"> </span><span class="c1">########## Clinton's face</span><span class="w"> </span><span class="n">blog_clinton</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read.csv</span><span class="p">(</span><span class="s2">"/your/file/path/clinton.csv"</span><span class="p">,</span><span class="w"> </span><span class="n">header</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">)</span><span class="w"> </span><span class="n">clinton_g</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">blog_clinton</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">gather</span><span class="p">(</span><span class="n">key</span><span class="p">,</span><span class="w"> </span><span class="n">value</span><span class="p">,</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="n">anger</span><span class="p">,</span><span class="w"> </span><span class="n">contempt</span><span class="p">,</span><span class="w"> </span><span class="n">disgust</span><span class="p">,</span><span class="w"> </span><span class="n">fear</span><span class="p">,</span><span class="w"> </span><span class="n">happiness</span><span class="p">,</span><span class="w"> </span><span class="n">neutral</span><span class="p">,</span><span class="w"> </span><span class="n">sadness</span><span class="p">,</span><span class="w"> </span><span class="n">surprise</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="o">!</span><span class="n">key</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"neutral"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">id</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="m">1</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">candidate</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Clinton"</span><span class="p">)</span><span class="w"> </span><span class="c1"># Merge them</span><span class="w"> </span><span class="n">all</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">rbind</span><span class="p">(</span><span class="n">clinton_g</span><span class="p">,</span><span class="w"> </span><span class="n">trump_g</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>Let’s visualize the data from whilom over time, via the measure of picture frames:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># Smooth line chart</span><span class="w"> </span><span class="n">ggplot</span><span class="p">(</span><span class="n">all</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">frame</span><span class="p">,</span><span class="w"> </span><span class="n">value</span><span class="p">,</span><span class="w"> </span><span class="n">group</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">key</span><span class="p">,</span><span class="w"> </span><span class="n">col</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">key</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="c1"># geom_line() + would exhibit all the non-smoothed lines</span><span class="w"> </span><span class="n">geom_smooth</span><span class="p">(</span><span class="n">method</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"loess"</span><span class="p">,</span><span class="w"> </span><span class="n">n</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">100000</span><span class="p">,</span><span class="w"> </span><span class="n">se</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">span</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.1</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">facet_wrap</span><span class="p">(</span><span class="o">~</span><span class="w"> </span><span class="n">candidate</span><span class="p">,</span><span class="w"> </span><span class="n">ncol</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">1</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme_minimal</span><span class="p">()</span><span class="w"> </span></code></pre></div></div> <p>Here’s the video we pulled out facial recognition data:</p> <iframe width="853" height="480" src="https://www.youtube.com/embed/IIw025m0c7U?rel=0&controls=0" frameborder="0" allowfullscreen=""> </iframe> <p>And when you run the script above, a wipe facet orchestration should towards for smoothed (assumed) facial emotions for both speakers, over the time interval of the last 5 minutes of the 3rd debate.</p> <p><img src="/images/face/plots/facial.png" alt="alt text" /></p> <p>Mr. Trump’s upset squatter was a sight many viewers got so used to over the previous debates, that it was no surprise for us to see him wrestling in the 3rd and final debate. Was this a strategic move, to intimidate his opponent and to pull up his chances to win credibility?</p> <p>Mark G. Frank, Professor and Chair of the Department of Communication at the State University of New York told me that most likely it is just his personal trait. What’s important for the interpretation of facial recognition data is the underlying context of spoken words or a reaction to what someone else has said. If the facial emotion measurement doesn’t match up with the sentiment in the speaker’s language, there is something wrong and worth to remoter investigate.</p> <p>There are occasions for both candidates when fake emotional expressions played an important role in their strategies. Trump unchangingly got what he wanted. In one of Trump’s book, “The Art of the Deal” reveals that in second grade he gave a teacher a woebegone eye. Today he uses his smart-ass instead of his fists, says it in the book. Are his wrestling and upset expression be a relict from his past when he got whatever he desired?</p> <p><img src="/images/face/trump.gif" alt="alt text" /></p> <p>Facial recognition data, as the one that we placid via the Microsoft emotion API, suggests that when Trump is challenged with arguments which he doesn’t like, his facial vein changes. In the second debate, Clinton provoked him with mentioning his involvement in degrading a former Miss Universe. His expression promptly reverted to a mixture of an wrestling and sad expression.</p> <p>On the contrary, there are unstipulated sequences when he seems to alimony his wrestling and sad squatter as a poker face. Frank calls for caution. When Trump pushes his lips together, his lip corners naturally go down. A facial recognition software is not necessarily smart and might pick up on muscle movements virtually Trumps corners. The software could incorrectly interpret it as sadness.</p> <h1 id="text-sentiment-vs-facial-sentiment">Text sentiment vs. facial sentiment</h1> <p>Like Professor Frank said, the facial recognition data interpretation depends a lot on the context, on what has been said. If we overlay a sentiment wringer of the last 5 minutes of the debate, we see that Hillary’s segments are positive, and so fits somewhat to her emotional state when her happiness level spikes virtually the 5,000 frames mark. Equally, Mr. Trump’s angriness level decreases in the final stage of the video we looked at, unescapable the 7,500 mark.</p> <blockquote> <p>(minute 4:15) Trump: We’re going to make America great. We have a depleted military. It has to be helped. It has to be fixed. We have the greatest people on Earth in our military. ></p> </blockquote> <p>This is mirrored with his reasoning on why the US healthcare system needs to be fixed, and in his subtitle there is no space for his sad or wrestling grimaces. It is increasingly worldwide for him to respond with these facial expressions when it was Mr. Clinton’s turn to speak (within the three segments in the middle of the video).</p> <h2 id="hillarys-fake-smile-stands-like-a-mexican-wall">Hillary’s fake smile stands like a Mexican wall</h2> <p>Hillary Clinton was revealed to own a facial pattern that might divert from what she unquestionably feels too. The software picked up on Clinton’s happy face, in moments when she isn’t told a joke. To understand her behaviour, we need to squint closer at the context. For occasions when Mr. Trump insulted her, she used her happy squatter as a wall to show him that he can’t unravel her to release real emotions, and she won’t let him get under her skin. Frank explains that Hillary Clinton’s response of smiling is a shielding struggle to stave mistakes such as feeling unstable or forgetting her point she needs to make. Trump tried everything to pry out an honest emotional response. He hoped to unnerve her, but she stood strong.</p> <p><img src="/images/face/plots/sentiment.png" alt="alt text" /></p> <h1 id="overall-sentiment-for-the-3rd-debate">Overall sentiment for the 3rd debate:</h1> <p>Lets have a final squint at the overall sentiment data. Since we have a script, it isn’t nonflexible to run it on the unshortened debate. We see that both Mr. Trump and Mrs. Clinton were playing on the negative side. The last 5 minutes we analysed their facial expressions on were relevant in my vision considering that is when their text sentiment delivered. Trump became increasingly negative, Clinton increasingly positive. And now we moreover know that her squatter was increasingly happy than his at that time.</p> <p><img src="/images/face/plots/sentiment_all2.png" alt="alt text" /></p> <h1 id="wrapping-up">Wrapping up:</h1> <p>The Microsoft emotion API, might be far yonder from stuff perfect. However, applying this technology to new reporting styles, could offer to have a variegated discussion well-nigh speakers, that could lead to new conclusions.</p> <p><img src="/images/face/beyonce.jpg" alt="alt text" /></p> <p>Whether facial recognition technology will be a crucial part of every future presidential debate, Frank wouldn’t answer. He was well-spoken on the results a facial recognition wringer could yield. A response can tell us something well-nigh a person. While for Mrs. Clinton, there is a lot of happiness tying in her struggle to baby-sit herself, Trump chose as his debate stage identity an wrestling grimace.</p>Ben Heubltechjournalism@gmail.comThe Microsoft Emotion API is based on state of the art research from Microsoft Research in computer vision and is based on a Deep Convolutional Neural Network model trained to classify the facial expressions of people in videos and images. This is an struggle to explain how to wield the API for data-driven reporting.Predicting who’s is to win the biggest skateboarding races in the world?2016-10-02T00:00:00+00:002016-10-02T00:00:00+00:00https://benheubl.github.io/machine%20learning/sls-win<p><strong>What is the strategy to win the word’s biggest Skateboarding event this year, the 2016 SLS Nike SB Super Crown World Championship: A combination of run and weightier trick skills. An wringer on previous events and scores, with a data-driven judgement on who might have the weightier chances to win</strong></p> <figure> <a href="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg"> <img src="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg" /> </a> <figcaption><a href="https://i.ytimg.com/vi/pzwT6lQ0sHE/maxresdefault.jpg" title="Street League 2013: Nyjah Huston">Street League 2013: Nyjah Huston</a>.</figcaption> </figure> <p>Skateboarding has had a bad reputation for many years surpassing Louis Vuitton used <a href="https://www.youtube.com/watch?v=GWydT-BNbQo">it in their ads</a>. Today, skateboarding manages to get sustentation from all corners of the media landscape, and is now plane only one step yonder to wilt an <a href="http://theridechannel.com/news/2016/06/skateboarding-olympics-tokyo-2020">Olympic discipline</a>. For decades, the typical competition format was that skaters were judged on their run, however Street league Skateboarding established a whole new data driven model to judge the performance of each street skater.</p> <p>Instead of only stuff ranked on the run on the skate course, SLS introduced a real time rating system, single tricks evaluation, and a statistical evaluation of the scoring for each skater.</p> <p><img src="https://benheubl.github.io/images/sls/skatetrick.gif" alt="pic1" /></p> <h1 id="sht-is-going-down-this-weekend-at-the-nike-sb-super-crown-world-championship">Sh.t is going lanugo this weekend, at the Nike SB Super Crown World Championship</h1> <p>This Sunday, the biggest street skateboarding competition will take place in LA. SLS is the official street skateboarding world championship as recognized by the International Skateboarding Federation. At the recent Street League Skateboarding Nike SB World Tour in Newark, New Jersey, <a href="http://streetleague.com/pros/nyjah-huston/">Nyjah Huston</a> won the game and is now defending the 2015 SLS Championship title. Could we yield some interesting findings that could support skaters with empirical vestige how to win it?</p> <p><img src="https://benheubl.github.io/images/sls/super_crown.png" alt="pic1" /></p> <p>Via a simple <a href="https://en.wikipedia.org/wiki/Exploratory_data_analysis">EDA</a>, we will try to establish a number of relevant patterns gained from previous SLS results.</p> <h1 id="relationships">Relationships</h1> <p>We understand from the correlation plot that there is a negative relationship between best-trick and run scores (-0.5), and an interesting one between age of skater and number of sponsors for each skater. Number of sponsors moreover plays nicely with final results for 2015 championship points.</p> <p><img src="https://benheubl.github.io/images/sls/plots/correlation2.png" alt="pic1" /></p> <h1 id="strategy">Strategy</h1> <p>Loess line seems to yank a variegated picture, than the linear regression line. We will consider the structure later, when towers a prediction model.</p> <p>SLS’s competition format requires a lot increasingly strategic planning today, than in the previous single score run-based competitions. An wringer of run-section and best-trick scores wideness recent Street League contests suggests that if players do perform well on either one of the sections, they usually perform not not as well in the other one (although, the linear trend is increasingly significant for the preliminaries).</p> <p><img src="https://benheubl.github.io/images/sls/plots/B_2.png" alt="pic1" /></p> <p>Chaz Ortiz and Shane O’Neill know how to perform well in the run section (mainly due to their vast wits in conventional skate contests), while Kevin Hoefler and Manny Santiago do well in the best-trick section. All-rounders such as Nyjah Huston and Luan Oliveira seem to do well in both sections for the finals. For the preliminaries, Shane and Nyjah leading the field, and are worldly-wise to make it into the finals every single time.</p> <h1 id="street-leagues-evolution">Street League’s evolution</h1> <p>Launched in 2010, Street League Skateboarding is now an international competitive series in professional skateboarding. The SLS ISX, which is the cadre of the concept, is weightier described as a real time scoring system, permitting to include each trick independently. This stands in unrelatedness to all other professional contests that judge on overall impression of a full run or series of tricks performed within a unrepealable time frame.Consideringthe outcome could transpiration to the very last trick, the regulars is kept in their seats. Transparency is upper too. If the regulars is worldly-wise to understand how and why the skaters were judged the way they were, it adds an spare kick. To win, skaters are required to to have a strategy and be smart well-nigh how they play their skills and their endurance.</p> <p><img src="https://benheubl.github.io/images/sls/plots/C.png" alt="pic1" /></p> <p>Comparing 2015 with 2016, Nyjah Huston’s run scores dropped slightly (this could be due to the fact that the scoring reverted overall).</p> <p><img src="https://benheubl.github.io/images/sls/plots/D.png" alt="pic1" /></p> <p>While Shane O’Neill could not modernize on his highest run scores (but on weightier trick scores)…</p> <p><img src="https://benheubl.github.io/images/sls/plots/E.png" alt="pic1" /></p> <p>…Paul Rodriguez kept performing well wideness both sections.</p> <p>If a skater is strikingly good at the run section, but fails to succeed in the weightier trick section (or vice versa), he (or she, sexuality Street League was introduced in 2015) is unlikely to win.</p> <p>So what is the weightier strategy? To wordplay the question, it helps to squint at statistical coefficients and relationships for data points for the previous events.</p> <h1 id="can-you-predict-win-probabilities-after-the-run-section">Can you predict win probabilities without the run section?</h1> <p>Ok, we learned something from a vital exploratory data analysis. It’s time to shift our sustentation to machine learning and use what we learned.</p> <p>Every SLS game starts with the run section, and ends with the weightier trick category. We could use machine learning and train one or multiple models to yield win probabilities without the run section, but surpassing the weightier trick section and utterance of a winner to predict the winner.</p> <p>In the next part our goal is to build multiple models, the practice to statistically compare them, and to come up with one that allows us to predict mid-game, which skater has the weightier changes to win the upcoming SLS Nike SB Super Crown World Championship.</p> <h2 id="defining-independent-and-dependent-variables">DefiningSelf-sustainingand dependent variables</h2> <p>The outcome variable we will predict is a win or no-win. An variation to this is towers a nomenclature models on podium winners (1st, 2nd, 3rd). In variegated corner of the SLS website, we find information on the <a href="http://streetleague.com/pros/">pro skaters</a>, their previous performances and <a href="http://streetleague.com/coverage/new-jersey-2016/">event-specific results</a>.</p> <p>From the <a href="http://streetleague.com/the-9-club/">SLS website</a>, we scrape the number of 9 club scores for each skater (9 Club tricks are the most no-go moments in Street League and represents the highest scores in previous contest). 9 club scores may moreover be an important predictor on how well the players did perform in the weightier trick section.</p> <p>Run HST and Run Avg may be important predictors to our models. Championship Points indulge new and established skaters to qualify into the SLS Nike SB Super Crown World Championship. Each skater’s point score will be fed to our model.</p> <p>We moreover throw in spare parameters. We have wangle to the age of some of the established pro skaters (the stereotype age of pros is virtually 25, but outliers such as Cole may skew it), we know their stance (goofy or regular), and in the process of scraping and cleaning, I was worldly-wise to count the number of sponsors.</p> <h1 id="model-types">Model types</h1> <p>We will build logic regression nomenclature models, and compare how well they are worldly-wise to perform versus each other.</p> <h2 id="logic-regression">Logic Regression</h2> <p>We will build and test a <a href="https://en.wikipedia.org/wiki/Binomial_regression">binomial logistic regression</a> (our outcome variable which can seem 2 values). The pursuit variables will be used to fit a <a href="https://stat.ethz.ch/R-manual/R-devel/library/stats/html/glm.html">GLM</a> model in R:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># Overview of variables:</span><span class="w"> </span><span class="n">glimpse</span><span class="p">(</span><span class="n">win</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>In a subconscious process, I have cleaned the data, and converted them to required matriculation types.Well-defineddata are factor values, while numerical are encoded as numerical or as an integer class. The age variable has no missing values anymore (<a href="http://stackoverflow.com/questions/7706876/remove-na-values-from-a-vector">removal of NA values in R</a>), and they have been replaced with the stereotype age values. Similarly, I dealt with the values in the stance post (to what stratum this is valid, needs to be evaluated, but for now, we don’t superintendency too much well-nigh stance - in theory, it shouldn’t make a difference whether a sunny skater is goofy or regular).</p> <p><img src="https://benheubl.github.io/images/sls/plots/lr_overview.png" alt="pic1" /></p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># randomize, sample training and test set:</span><span class="w"> </span><span class="n">set.seed</span><span class="p">(</span><span class="m">10</span><span class="p">)</span><span class="w"> </span><span class="n">win_r</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">sample_n</span><span class="p">(</span><span class="n">win</span><span class="p">,</span><span class="w"> </span><span class="m">207</span><span class="p">)</span><span class="w"> </span><span class="n">train</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">win_r</span><span class="p">[</span><span class="m">1</span><span class="o">:</span><span class="m">150</span><span class="p">,]</span><span class="w"> </span><span class="n">test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">win_r</span><span class="p">[</span><span class="m">151</span><span class="o">:</span><span class="m">207</span><span class="p">,]</span><span class="w"> </span><span class="c1"># fit GLM model:</span><span class="w"> </span><span class="n">model</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">glm</span><span class="p">(</span><span class="n">class_winner</span><span class="w"> </span><span class="o">~</span><span class="n">.</span><span class="p">,</span><span class="n">family</span><span class="o">=</span><span class="n">binomial</span><span class="p">(</span><span class="n">link</span><span class="o">=</span><span class="s1">'logit'</span><span class="p">),</span><span class="n">data</span><span class="o">=</span><span class="n">train</span><span class="p">)</span><span class="w"> </span><span class="n">summary</span><span class="p">(</span><span class="n">model</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p><img src="https://benheubl.github.io/images/sls/plots/lr_fitting.png" alt="pic1" /></p> <p>We learn from the summary function that most of the variables are not statistically significant for our model. Run_HST is possibly the weightier predictor we can use at this stage. A positive coefficient for Run_HST suggests - if other variables are kept equal - that a unit increase in highest run section scores would increase the odds to win by 4.740e+00.</p> <p>We run a function from the Anova package, to investigate the table of deviance:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">anova</span><span class="p">(</span><span class="n">model</span><span class="p">,</span><span class="w"> </span><span class="n">test</span><span class="o">=</span><span class="s2">"Chisq"</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p><img src="https://benheubl.github.io/images/sls/plots/lr_deviance.png" alt="pic1" /></p> <p>This gives us an idea on how well our GLM model performs agains the null model. Here we see that not only Run_HST reduced the residual deviance, but moreover the variables age and champ_pts_2015. For us it is important to see a significant subtract in deviance. Lets assess the model’s fit via McFadden R-Squared measure:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">install.packages</span><span class="p">(</span><span class="s2">"pscl"</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">pscl</span><span class="p">)</span><span class="w"> </span><span class="n">pR2</span><span class="p">(</span><span class="n">model</span><span class="p">)</span><span class="w"> </span><span class="n">llh</span><span class="w"> </span><span class="n">llhNull</span><span class="w"> </span><span class="n">G</span><span class="m">2</span><span class="w"> </span><span class="n">McFadden</span><span class="w"> </span><span class="n">r</span><span class="m">2</span><span class="n">ML</span><span class="w"> </span><span class="n">r</span><span class="m">2</span><span class="n">CU</span><span class="w"> </span><span class="m">-14.2949557</span><span class="w"> </span><span class="m">-36.7395040</span><span class="w"> </span><span class="m">44.8890966</span><span class="w"> </span><span class="m">0.6109105</span><span class="w"> </span><span class="m">0.2586338</span><span class="w"> </span><span class="m">0.6678078</span><span class="w"> </span></code></pre></div></div> <p>This yields a McFadden score of 0.611, which might be comparable to a linear regression’s R-Squared metric.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># Run on test data:</span><span class="w"> </span><span class="n">test_run</span><span class="o"><-</span><span class="n">test</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="o">-</span><span class="n">class_winner</span><span class="p">)</span><span class="w"> </span><span class="n">fitted.results</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">predict</span><span class="p">(</span><span class="n">model</span><span class="p">,</span><span class="n">test_run</span><span class="p">,</span><span class="w"> </span><span class="n">type</span><span class="o">=</span><span class="s1">'response'</span><span class="p">)</span><span class="w"> </span><span class="n">fitted.results</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">ifelse</span><span class="p">(</span><span class="n">fitted.results</span><span class="w"> </span><span class="o">></span><span class="w"> </span><span class="m">0.5</span><span class="p">,</span><span class="m">1</span><span class="p">,</span><span class="m">0</span><span class="p">)</span><span class="w"> </span><span class="n">misClasificError</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">mean</span><span class="p">(</span><span class="n">fitted.results</span><span class="w"> </span><span class="o">!=</span><span class="w"> </span><span class="n">test</span><span class="o">$</span><span class="n">class_winner</span><span class="p">)</span><span class="w"> </span><span class="n">misClasificError</span><span class="w"> </span><span class="n">print</span><span class="p">(</span><span class="n">paste</span><span class="p">(</span><span class="s1">'Accuracy'</span><span class="p">,</span><span class="m">1</span><span class="o">-</span><span class="n">misClasificError</span><span class="p">))</span><span class="w"> </span><span class="c1">#[1] "Accuracy 0.912280701754386"</span><span class="w"> </span><span class="c1">#CrossTable:</span><span class="w"> </span><span class="n">CrossTable</span><span class="p">(</span><span class="n">fitted.results</span><span class="p">,</span><span class="w"> </span><span class="n">test</span><span class="o">$</span><span class="n">class_winner</span><span class="p">,</span><span class="w"> </span><span class="n">prop.chisq</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">prop.t</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">dnn</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="s2">"Predicted"</span><span class="p">,</span><span class="w"> </span><span class="s2">"Actual"</span><span class="p">))</span><span class="w"> </span></code></pre></div></div> <p>While we get an verism of 91%, this result is misleading. The model couldn’t find who is going to win. Only who is not to win, which isn’t really our problem at this stage, but one reason we get such upper verism score.</p> <p><img src="https://benheubl.github.io/images/sls/plots/lr_winner_poor.png" alt="pic1" /></p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">ctrl</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">trainControl</span><span class="p">(</span><span class="n">method</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"repeatedcv"</span><span class="p">,</span><span class="w"> </span><span class="n">number</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">10</span><span class="p">,</span><span class="w"> </span><span class="n">savePredictions</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="kc">TRUE</span><span class="p">)</span><span class="w"> </span><span class="n">mod_fit</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">train</span><span class="p">(</span><span class="n">class_winner</span><span class="w"> </span><span class="o">~</span><span class="n">.</span><span class="p">,</span><span class="w"> </span><span class="n">data</span><span class="o">=</span><span class="n">win_r</span><span class="p">,</span><span class="w"> </span><span class="n">method</span><span class="o">=</span><span class="s2">"glm"</span><span class="p">,</span><span class="w"> </span><span class="n">family</span><span class="o">=</span><span class="s2">"binomial"</span><span class="p">,</span><span class="w"> </span><span class="n">trControl</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">ctrl</span><span class="p">,</span><span class="w"> </span><span class="n">tuneLength</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">5</span><span class="p">)</span><span class="w"> </span><span class="n">pred</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">predict</span><span class="p">(</span><span class="n">mod_fit</span><span class="p">,</span><span class="w"> </span><span class="n">newdata</span><span class="o">=</span><span class="n">test</span><span class="p">)</span><span class="w"> </span><span class="n">confusionMatrix</span><span class="p">(</span><span class="n">data</span><span class="o">=</span><span class="n">pred</span><span class="p">,</span><span class="w"> </span><span class="n">test</span><span class="o">$</span><span class="n">class_winner</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>We can personize the verism result with K-Fold navigate validation, a inside model performance metric in machine learning. We wield one of the most worldwide variation of navigate validation, the 10-fold cross-validation and exhibit the result via a ravages matrix. Now we get an plane higher verism score of 95 percent. Still, the model couldn’t find the winners.</p> <p><img src="https://benheubl.github.io/images/sls/plots/ls_cross_validation.png" alt="pic1" /></p> <h2 id="predicting-winning-a-medal">Predicting winning a medal:</h2> <p>The data only covers two years of the games. This makes it nonflexible for a model like this to spot winners. What we could be doing instead is to tune lanugo our standards, and only squint for the lucky three winners who make it onto a podium. For that, we need to summate an uneaten column, and add a “1”, for all skaters who made it among the top three, and “0” for the ones that didn’t. To test our new model, we will run it on the most recent game in New Jersey, without cleaning the training data.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="w"> </span><span class="n">set.seed</span><span class="p">(</span><span class="m">10</span><span class="p">)</span><span class="w"> </span><span class="n">win_r</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">sample_n</span><span class="p">(</span><span class="n">test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">win</span><span class="p">[</span><span class="nf">c</span><span class="p">(</span><span class="m">1</span><span class="o">:</span><span class="m">68</span><span class="p">,</span><span class="w"> </span><span class="m">77</span><span class="o">:</span><span class="m">207</span><span class="p">),],</span><span class="w"> </span><span class="m">199</span><span class="p">)</span><span class="w"> </span><span class="n">train</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">win_r</span><span class="w"> </span><span class="n">test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">win</span><span class="p">[</span><span class="m">69</span><span class="o">:</span><span class="m">76</span><span class="p">,]</span><span class="w"> </span><span class="c1">##New-Jersey-2016</span><span class="w"> </span><span class="n">model</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">glm</span><span class="p">(</span><span class="n">top_3_outcome</span><span class="w"> </span><span class="o">~</span><span class="n">.</span><span class="p">,</span><span class="n">family</span><span class="o">=</span><span class="n">binomial</span><span class="p">(</span><span class="n">link</span><span class="o">=</span><span class="s1">'logit'</span><span class="p">),</span><span class="n">data</span><span class="o">=</span><span class="n">train</span><span class="p">)</span><span class="w"> </span><span class="n">test_run</span><span class="o"><-</span><span class="n">test</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="o">-</span><span class="n">top_3_outcome</span><span class="p">)</span><span class="w"> </span><span class="n">fitted.results</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">predict</span><span class="p">(</span><span class="n">model</span><span class="p">,</span><span class="n">test_run</span><span class="p">,</span><span class="w"> </span><span class="n">type</span><span class="o">=</span><span class="s1">'response'</span><span class="p">)</span><span class="w"> </span><span class="n">fitted.results</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">ifelse</span><span class="p">(</span><span class="n">fitted.results</span><span class="w"> </span><span class="o">></span><span class="w"> </span><span class="m">0.5</span><span class="p">,</span><span class="m">1</span><span class="p">,</span><span class="m">0</span><span class="p">)</span><span class="w"> </span><span class="n">misClasificError</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">mean</span><span class="p">(</span><span class="n">fitted.results</span><span class="w"> </span><span class="o">!=</span><span class="w"> </span><span class="n">test</span><span class="o">$</span><span class="n">top_3_outcome</span><span class="p">)</span><span class="w"> </span><span class="n">print</span><span class="p">(</span><span class="n">paste</span><span class="p">(</span><span class="s1">'Accuracy'</span><span class="p">,</span><span class="m">1</span><span class="o">-</span><span class="n">misClasificError</span><span class="p">))</span><span class="w"> </span><span class="c1">#[1] "Accuracy 0.75"</span><span class="w"> </span><span class="c1">#CrossTable:</span><span class="w"> </span><span class="n">CrossTable</span><span class="p">(</span><span class="n">fitted.results</span><span class="p">,</span><span class="w"> </span><span class="n">test</span><span class="o">$</span><span class="n">top_3_outcome</span><span class="p">,</span><span class="w"> </span><span class="n">prop.chisq</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">prop.t</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">dnn</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="s2">"Predicted"</span><span class="p">,</span><span class="w"> </span><span class="s2">"Actual"</span><span class="p">))</span><span class="w"> </span></code></pre></div></div> <p><img src="https://benheubl.github.io/images/sls/plots/jersey.png" alt="pic1" /></p> <p>This model performs better. Except of 2 miss-classified instances, we got 2 out of 3 podium winners right. While it did well on the two winners - Nyjah Huston (1st), Chris Joslin (2nd), with 90% and 80% probability respectively - the model could not icon out the third place, that was labelled as “other” in our training data. Tommy Fynn was not included in the practice when I labelling the rank_skater post (skaters that will play Sunday’s finals were labelled in the data). As good practice requires, we will squint at is ROC lines to produce a visual representation for the AUC, a performance measurements for a binary classifier.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">install.packages</span><span class="p">(</span><span class="s2">"ROCR"</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">ROCR</span><span class="p">)</span><span class="w"> </span><span class="n">fitted.results</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">predict</span><span class="p">(</span><span class="n">model</span><span class="p">,</span><span class="n">test_run</span><span class="p">,</span><span class="w"> </span><span class="n">type</span><span class="o">=</span><span class="s1">'response'</span><span class="p">)</span><span class="w"> </span><span class="n">fitted_for_ROCR</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">prediction</span><span class="p">(</span><span class="n">fitted.results</span><span class="p">,</span><span class="w"> </span><span class="n">test</span><span class="o">$</span><span class="n">top_3_outcome</span><span class="p">)</span><span class="w"> </span><span class="n">performance_ROCR</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">performance</span><span class="p">(</span><span class="n">pr</span><span class="p">,</span><span class="w"> </span><span class="n">measure</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"tpr"</span><span class="p">,</span><span class="w"> </span><span class="n">x.measure</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"fpr"</span><span class="p">)</span><span class="w"> </span><span class="c1"># plot:</span><span class="w"> </span><span class="n">plot</span><span class="p">(</span><span class="n">prf</span><span class="p">)</span><span class="w"> </span><span class="n">AUC</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">performance</span><span class="p">(</span><span class="n">fitted.results</span><span class="p">,</span><span class="w"> </span><span class="n">measure</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"auc"</span><span class="p">)</span><span class="w"> </span><span class="n">AUC</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">auc</span><span class="o">@</span><span class="n">y.values</span><span class="p">[[</span><span class="m">1</span><span class="p">]]</span><span class="w"> </span><span class="c1">#[1] 0.7333333</span><span class="w"> </span></code></pre></div></div> <p><img src="https://benheubl.github.io/images/sls/plots/ROCR.png" alt="pic1" /></p> <p>An AUC of 0.73 is not entirely pleasing, but it’s a start. We could now squint for which score each skater on Sunday would need to proceeds for decent win probability. For this, we could build a test-set with the skater names and run scores ranging from 1 to 10 (we once know that skater and Run_HST are powerful predictors for the podium medals).</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1">### probabilities for highest scores:</span><span class="w"> </span><span class="n">scores</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">seq</span><span class="p">(</span><span class="m">1</span><span class="p">,</span><span class="w"> </span><span class="m">10</span><span class="p">,</span><span class="w"> </span><span class="m">0.1</span><span class="p">)</span><span class="w"> </span><span class="n">skaters</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="s2">"NyjahHuston"</span><span class="p">,</span><span class="w"> </span><span class="s2">"ShaneONeill"</span><span class="p">,</span><span class="w"> </span><span class="s2">"PaulRodriguez"</span><span class="p">,</span><span class="w"> </span><span class="s2">"LuanOliveira"</span><span class="p">,</span><span class="w"> </span><span class="s2">"TomAsta"</span><span class="p">,</span><span class="w"> </span><span class="s2">"RyanDecenzo"</span><span class="p">,</span><span class="w"> </span><span class="s2">"CodyMcEntire"</span><span class="p">,</span><span class="w"> </span><span class="s2">"ChrisJoslin"</span><span class="p">)</span><span class="w"> </span><span class="n">df_skate</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="kc">NULL</span><span class="w"> </span><span class="k">for</span><span class="w"> </span><span class="p">(</span><span class="n">skater</span><span class="w"> </span><span class="k">in</span><span class="w"> </span><span class="m">1</span><span class="o">:</span><span class="nf">length</span><span class="p">(</span><span class="n">skaters</span><span class="p">))</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="k">for</span><span class="w"> </span><span class="p">(</span><span class="n">s</span><span class="w"> </span><span class="k">in</span><span class="w"> </span><span class="m">1</span><span class="o">:</span><span class="nf">length</span><span class="p">(</span><span class="n">scores</span><span class="p">))</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">df_skate</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">rbind</span><span class="p">(</span><span class="n">df_skate</span><span class="p">,</span><span class="w"> </span><span class="n">cbind</span><span class="p">(</span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">scores</span><span class="p">[</span><span class="n">s</span><span class="p">]),</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">skaters</span><span class="p">[</span><span class="n">skater</span><span class="p">])))</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="nf">names</span><span class="p">(</span><span class="n">df_skate</span><span class="p">)[</span><span class="m">1</span><span class="p">]</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="s2">"Run_HST"</span><span class="w"> </span><span class="nf">names</span><span class="p">(</span><span class="n">df_skate</span><span class="p">)[</span><span class="m">2</span><span class="p">]</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="s2">"rank_skater"</span><span class="w"> </span><span class="n">fitted.results</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">predict</span><span class="p">(</span><span class="n">model</span><span class="p">,</span><span class="n">df_skate</span><span class="p">,</span><span class="w"> </span><span class="n">type</span><span class="o">=</span><span class="s1">'response'</span><span class="p">)</span><span class="w"> </span><span class="c1"># with Run_HST and rank_skater as input variables</span><span class="w"> </span><span class="n">ggplot</span><span class="p">(</span><span class="n">props</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">Run_HST</span><span class="p">,</span><span class="w"> </span><span class="n">fitted.results</span><span class="p">,</span><span class="w"> </span><span class="n">group</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">rank_skater</span><span class="p">,</span><span class="w"> </span><span class="n">col</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">rank_skater</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_line</span><span class="p">()</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme_minimal</span><span class="p">()</span><span class="w"> </span></code></pre></div></div> <p><img src="https://benheubl.github.io/images/sls/plots/props_skaters_lr.png" alt="pic1" /></p> <p>Win probabilities orchestration for each skater from their highest run scores.</p> <h1 id="wrapping-up">Wrapping up</h1> <p>As we have seen, Nyjah Huston, Shane O’Neill and Paul Rodriguez do have weightier chances to make it on the podium. In which combination is unclear, but we will find out shortly. We have moreover learned how to wield a logistic regression on skateboarding, and how to compare the results wideness the various types of models we build. Two increasingly models have been built. A neural network model and a random forrest model, both which didn’t perform as well as the logistic regression.</p>Ben Heubltechjournalism@gmail.comWhat is the strategy to win the word’s biggest Skateboarding event this year, the 2016 SLS Nike SB Super Crown World Championship: A combination of run and weightier trick skills. An wringer on previous events and scores, with a data-driven judgement on who might have the weightier chances to winBuilding a model to spot how unique Hillary Clinton really is2016-09-26T00:00:00+00:002016-09-26T00:00:00+00:00https://benheubl.github.io/machine%20learning/navie-bayes<p><strong>How unique is Hillary Clinton’s style? What does her speeches tell us well-nigh her uniqueness? In this post I built several Naive Bayes models, trained them on Hillary’s 2016 wayfarers speeches and unromantic them on other remarks, tweets and text corpuses. The results is Interesting, and presents flipside journalistic use-case for machine learning.</strong></p> <p><img src="/images/naive/header.jpg" alt="alt text" /></p> <p>I sometimes have a nonflexible time to find applications for machine learning in data journalism. While models can help to predict future data points upon past observations, sometimes there is simply not a unconfined use-cases that would tell readers anything new. I am increasingly hopeful when it comes to text analysis. Text is everywhere. Text is part of the presidential rally, and text is part of every journalist reporting well-nigh it. And there is moreover too much text data, for everyone to read and process. Here, the use of streamlined data analytics and machine learning could contribute unconfined value and new meaningful insight. A start has been made with an <a href="http://benheubl.github.io/data%20analysis/strategy-to-speak/">earlier post</a>.</p> <h1 id="naive-bayes-for-text-analysis">Naive Bayes for text analysis</h1> <p>Here, I use machine learning to make a judgement on Hillary Clinton’s uniqueness. How? By using her 2016 wayfarers speeches from Clinton’s wayfarers website, by mixing it up with speeches from other US presidents (including some of her husband’s speeches), and by training a fairly simple <a href="https://en.wikipedia.org/wiki/Naive_Bayes_classifier">Naive Bayes model</a> by applying a “Bag of Words” methodology (<a href="https://www.datacamp.com/courses/intro-to-text-mining-bag-of-words">here</a> a good tutorial to follow), we can observe how easy for the computer model it is to filter out her speeches and comments from others.</p> <p><img src="/images/naive/clinton_happy.gif" alt="alt text" /></p> <p>In theory, if the model doesn’t preform well, Hillary Clinton’s speeches - including her words and phrases and topics - could be very similar to other political speakers. From here, we could judge her on for stuff not unique enough, and not worldly-wise to voice her own though and words unbearable of the time (whatever that might mean). Many US voters these days, I am convinced value a presidential candidate who is herself, as we can see from the popularity of Donal Trump (who is all himself, in any speech or interview).</p> <p>On the contrary, if the model doesn’t do well, I may either vituperation myself on wrongly calibrating the model, or vituperation the state of the text data collected. If we could provide vestige that Hillary Clinton’s speeches are unique unbearable - in the sense that the classifying model is doing well - we can proof that she is who she claims to be.</p> <h2 id="the-catch">The catch</h2> <p>The tideway has some hooks. As we only wield a bag of words methodology, the most frequent words have a greater impact on the classifier. The dates the speeches were delivered have not been taken into worth either. Applying Naive Bayes (NB), has some spare drawbacks:</p> <ul> <li>While the Naive Bayes classifier is said to be fast, and very effective, worldly-wise to deal with noisy and missing data and requests relatively few examples for training (it is easy to moreover obtain the unscientific probability for a prediction),</li> <li>it relies on an often-faulty theorizing of equally important and self-sustaining features. NB isn’t platonic for datasets with many numeric features and unscientific probabilities are less reliable than the predicted classes.</li> </ul> <p><img src="/images/naive/nb.jpg" alt="alt text" /></p> <p>I will run you through the process on how prepare text data and how to classify Hillary’s speeches and text documents. For this, we will squint at how well NB can perform on text nomenclature for the following:</p> <ul> <li>find her speeches in a pile mixed up with her husband’s Bill (Is she unique unbearable for the algorithm to spot hers?)</li> <li>Hillary’s own speeches from the time when she was Secretary of State (giving clues well-nigh whether she might have “changed her style” over the past years)</li> <li>and on Hillary’s recent tweets (could we spot which tweets she may not have written herself?)</li> </ul> <h1 id="get-the-data">Get the data:</h1> <p>To train a Naive Bayes model, we need text data. We fetch it from Hillary’s wayfarers <a href="https://www.hillaryclinton.com/" title="link">website</a>.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># Clinton 2016 speeches from Hillaryclinton.com:</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">xml2</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">rvest</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">dplyr</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">tidyr</span><span class="p">)</span><span class="w"> </span><span class="n">url1</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="s2">"https://www.hillaryclinton.com/speeches/page/"</span><span class="w"> </span><span class="n">get_linkt</span><span class="o"><-</span><span class="w"> </span><span class="k">function</span><span class="w"> </span><span class="p">(</span><span class="n">ur</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">red_t</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read_html</span><span class="p">(</span><span class="n">ur</span><span class="p">)</span><span class="w"> </span><span class="n">speech</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">red_t</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_nodes</span><span class="p">(</span><span class="s2">".o-post-no-img"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_attr</span><span class="p">(</span><span class="s2">"href"</span><span class="p">)</span><span class="w"> </span><span class="nf">return</span><span class="p">(</span><span class="n">paste0</span><span class="p">(</span><span class="s2">"https://www.hillaryclinton.com"</span><span class="p">,</span><span class="w"> </span><span class="n">speech</span><span class="p">,</span><span class="w"> </span><span class="n">sep</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">""</span><span class="p">))</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="n">df_clinton_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="kc">NULL</span><span class="w"> </span><span class="k">for</span><span class="w"> </span><span class="p">(</span><span class="n">t</span><span class="w"> </span><span class="k">in</span><span class="w"> </span><span class="m">1</span><span class="o">:</span><span class="m">10</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">linkt</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">paste0</span><span class="p">(</span><span class="n">url1</span><span class="p">,</span><span class="w"> </span><span class="n">t</span><span class="p">,</span><span class="w"> </span><span class="s2">"/"</span><span class="p">,</span><span class="w"> </span><span class="n">sep</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">""</span><span class="p">)</span><span class="w"> </span><span class="n">print</span><span class="p">(</span><span class="n">linkt</span><span class="p">)</span><span class="w"> </span><span class="n">df_clinton_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">rbind</span><span class="p">(</span><span class="n">df_clinton_2016</span><span class="p">,</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">get_linkt</span><span class="p">(</span><span class="n">linkt</span><span class="p">)))</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="n">getspe</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="k">function</span><span class="w"> </span><span class="p">(</span><span class="n">urs</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">red_p</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read_html</span><span class="p">(</span><span class="n">urs</span><span class="p">)</span><span class="w"> </span><span class="n">speech1</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">red_p</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_nodes</span><span class="p">(</span><span class="s2">".s-wysiwyg"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_text</span><span class="p">()</span><span class="w"> </span><span class="nf">as.character</span><span class="p">(</span><span class="n">speech1</span><span class="p">)</span><span class="w"> </span><span class="n">wann</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">red_p</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_node</span><span class="p">(</span><span class="s2">"time"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_text</span><span class="p">()</span><span class="w"> </span><span class="nf">as.character</span><span class="p">(</span><span class="n">wann</span><span class="p">)</span><span class="w"> </span><span class="n">dataframs</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">cbind</span><span class="p">(</span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">speech1</span><span class="p">),</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">wann</span><span class="p">))</span><span class="w"> </span><span class="nf">return</span><span class="p">(</span><span class="n">dataframs</span><span class="p">)</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="n">fin_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="kc">NULL</span><span class="w"> </span><span class="k">for</span><span class="w"> </span><span class="p">(</span><span class="n">p</span><span class="w"> </span><span class="k">in</span><span class="w"> </span><span class="m">1</span><span class="o">:</span><span class="n">nrow</span><span class="p">(</span><span class="n">df_clinton_2016</span><span class="p">))</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">tryCatch</span><span class="p">({</span><span class="w"> </span><span class="n">linkp</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">df_clinton_2016</span><span class="p">[</span><span class="n">p</span><span class="p">,</span><span class="w"> </span><span class="m">1</span><span class="p">]</span><span class="w"> </span><span class="n">print</span><span class="p">(</span><span class="n">linkp</span><span class="p">)</span><span class="w"> </span><span class="n">fin_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">rbind</span><span class="p">(</span><span class="n">fin_2016</span><span class="p">,</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">getspe</span><span class="p">(</span><span class="nf">as.character</span><span class="p">(</span><span class="n">linkp</span><span class="p">))))</span><span class="w"> </span><span class="p">},</span><span class="w"> </span><span class="n">error</span><span class="o">=</span><span class="k">function</span><span class="p">(</span><span class="n">e</span><span class="p">){</span><span class="n">cat</span><span class="p">(</span><span class="s2">"ERROR :"</span><span class="p">,</span><span class="n">conditionMessage</span><span class="p">(</span><span class="n">e</span><span class="p">),</span><span class="w"> </span><span class="s2">"\n"</span><span class="p">)})</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="n">get_speech_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="k">function</span><span class="w"> </span><span class="p">(</span><span class="n">u</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">red_s</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read_html</span><span class="p">(</span><span class="n">u</span><span class="p">)</span><span class="w"> </span><span class="n">speech</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">red_s</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_nodes</span><span class="p">()</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_text</span><span class="p">()</span><span class="w"> </span><span class="n">wann</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">red_s</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_nodes</span><span class="p">()</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_text</span><span class="p">()</span><span class="w"> </span><span class="n">wo</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">red_s</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_nodes</span><span class="p">()</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_text</span><span class="p">()</span><span class="w"> </span><span class="n">bingins</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">cbind</span><span class="p">(</span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">speech</span><span class="p">),</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">wann</span><span class="p">),</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">wo</span><span class="p">))</span><span class="w"> </span><span class="p">}</span><span class="w"> </span></code></pre></div></div> <h1 id="is-hillary-only-a-new-bill">Is Hillary only a new Bill?</h1> <p>How variegated is her speech content from Bill Clinton’s. How unique are the messages she is sending out in her 2016 wayfarers speeches compared to her husband’s? First we will wipe and then train and test the NB on a dataset that contains both Hillary’s and Bill’s speeches.</p> <h2 id="text-data-fetching">Text data fetching:</h2> <p>For each part of this post, we will both train the model, and then classify the test set, resulting in a judgement on how well the model does on the new data. For this we need our data to be clean. For sit-in purposes, we will do it here once, but skip over it later on.</p> <p>First off, I used this <a href="http://millercenter.org/president/speeches">website</a> to scrape some of Bill Clinton’s speeches (Bill’s speeches might not be the weightier (e.g. speeches that occured at a variegated time maybe variegated by its nature, the topics he spoke well-nigh when then differ from today’s, and they differ in gender). However, they are living together. One might assume, that Bill may have rubbed off on Hillary without all those years. Let’s mix them up first with Hillary’s 2016 speeches:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="w"> </span><span class="n">ge_links</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="k">function</span><span class="w"> </span><span class="p">(</span><span class="n">x</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">t</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read_html</span><span class="p">(</span><span class="n">x</span><span class="p">)</span><span class="w"> </span><span class="n">linky</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">t</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_nodes</span><span class="p">(</span><span class="s2">".title a"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_attr</span><span class="p">(</span><span class="s2">"href"</span><span class="p">)</span><span class="w"> </span><span class="nf">return</span><span class="p">(</span><span class="n">paste0</span><span class="p">(</span><span class="s2">"http://millercenter.org"</span><span class="p">,</span><span class="w"> </span><span class="n">linky</span><span class="p">,</span><span class="w"> </span><span class="n">sep</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">""</span><span class="p">))</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="n">url_pre</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="s2">"http://millercenter.org/president/speeches"</span><span class="w"> </span><span class="n">df_pres</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="kc">NULL</span><span class="w"> </span><span class="n">df_pres</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">rbind</span><span class="p">(</span><span class="n">df_pres</span><span class="p">,</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">paste0</span><span class="p">(</span><span class="s2">""</span><span class="p">,</span><span class="w"> </span><span class="n">ge_links</span><span class="p">(</span><span class="n">url_pre</span><span class="p">),</span><span class="w"> </span><span class="n">sep</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">""</span><span class="p">)))</span><span class="w"> </span><span class="c1">######### transpiration post with post id</span><span class="w"> </span><span class="nf">names</span><span class="p">(</span><span class="n">df_pres</span><span class="p">)[</span><span class="m">1</span><span class="p">]</span><span class="o"><-</span><span class="s2">"link"</span><span class="w"> </span><span class="n">View</span><span class="p">(</span><span class="n">df_pres</span><span class="p">)</span><span class="w"> </span><span class="n">get_speech_pres</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="k">function</span><span class="w"> </span><span class="p">(</span><span class="n">x</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">t</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read_html</span><span class="p">(</span><span class="n">x</span><span class="p">)</span><span class="w"> </span><span class="n">speech</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">t</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_node</span><span class="p">(</span><span class="s2">"#transcript"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">html_text</span><span class="p">()</span><span class="w"> </span><span class="nf">return</span><span class="p">(</span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">speech</span><span class="p">))</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="n">get_speech_pres</span><span class="p">(</span><span class="s2">"http://millercenter.org/president/washington/speeches/speech-3459"</span><span class="p">)</span><span class="w"> </span><span class="n">df_speeches2</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="kc">NULL</span><span class="w"> </span><span class="k">for</span><span class="w"> </span><span class="p">(</span><span class="n">y</span><span class="w"> </span><span class="k">in</span><span class="w"> </span><span class="m">90</span><span class="o">:</span><span class="m">128</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">print</span><span class="p">(</span><span class="n">y</span><span class="p">)</span><span class="w"> </span><span class="n">tryCatch</span><span class="p">({</span><span class="w"> </span><span class="n">link_y</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">as.character</span><span class="p">(</span><span class="n">df_pres</span><span class="p">[</span><span class="n">y</span><span class="p">,</span><span class="w"> </span><span class="m">1</span><span class="p">])</span><span class="w"> </span><span class="n">df_speeches2</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">rbind</span><span class="p">(</span><span class="n">df_speeches2</span><span class="p">,</span><span class="w"> </span><span class="p">(</span><span class="n">get_speech_pres</span><span class="p">(</span><span class="n">link_y</span><span class="p">)))</span><span class="w"> </span><span class="p">},</span><span class="w"> </span><span class="n">error</span><span class="o">=</span><span class="k">function</span><span class="p">(</span><span class="n">e</span><span class="p">){</span><span class="n">cat</span><span class="p">(</span><span class="s2">"ERROR :"</span><span class="p">,</span><span class="n">conditionMessage</span><span class="p">(</span><span class="n">e</span><span class="p">),</span><span class="w"> </span><span class="s2">"\n"</span><span class="p">)})</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="c1"># Build a worldwide structure - type and text as columns:</span><span class="w"> </span><span class="n">Bills</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">df_speeches2</span><span class="w"> </span><span class="c1"># Bill's speeches</span><span class="w"> </span><span class="n">Bills</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">Bills</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">type</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Bill"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">text</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">speech</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="o">-</span><span class="n">speech</span><span class="p">)</span><span class="w"> </span><span class="n">Hillary_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">fin_2016</span><span class="w"> </span><span class="c1"># Hillary's speeches</span><span class="w"> </span><span class="n">Hillary_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">Hillary_2016</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="n">speech1</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">type</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Hillary"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">text</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">speech1</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="o">-</span><span class="n">speech1</span><span class="p">)</span><span class="w"> </span><span class="c1"># rbind them (concatenate them):</span><span class="w"> </span><span class="n">bill_hillary</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">rbind</span><span class="p">(</span><span class="n">Hillary_2016</span><span class="p">,</span><span class="w"> </span><span class="n">Bills</span><span class="p">)</span><span class="w"> </span><span class="c1"># Mix them up - wield a random sampling function</span><span class="w"> </span><span class="n">nrow</span><span class="p">(</span><span class="n">final_clintons</span><span class="p">)</span><span class="w"> </span><span class="c1"># [1] 135</span><span class="w"> </span><span class="n">bill_hillary_random</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">sample_n</span><span class="p">(</span><span class="n">bill_hillary</span><span class="p">,</span><span class="w"> </span><span class="m">135</span><span class="p">)</span><span class="w"> </span><span class="c1"># sample_n, a unconfined dplyr function for random sampling</span><span class="w"> </span></code></pre></div></div> <h1 id="clean-the-data">Clean the data:</h1> <p>To help with data cleaning, the text processing package ‘tm’ by Ingo Feinerer is of unconfined help. To start things off, we need a corpus, a simple hodgepodge of text documents. We use the VCorpus() function in the tm package without we convert the features in the post type into the data format of type factor.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">NLP</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">tm</span><span class="p">)</span><span class="w"> </span><span class="c1"># Convert type post into as.factor()</span><span class="w"> </span><span class="n">bill_hillary_random</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">bill_hillary_random</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">type</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">factor</span><span class="p">(</span><span class="n">type</span><span class="p">))</span><span class="w"> </span><span class="c1">#Trammelsdistributions:</span><span class="w"> </span><span class="n">prop.table</span><span class="p">(</span><span class="n">table</span><span class="p">(</span><span class="n">bill_hillary_random</span><span class="o">$</span><span class="n">type</span><span class="p">))</span><span class="w"> </span><span class="c1"># 28% are Bills speeches, the rest are Hillary's</span><span class="w"> </span><span class="n">Bill</span><span class="w"> </span><span class="n">Hillary</span><span class="w"> </span><span class="m">0.2888889</span><span class="w"> </span><span class="m">0.7111111</span><span class="w"> </span></code></pre></div></div> <p>We use the VectorSource() reader function to create a source object from the existing hil_bill$text vector, which can then be converted via VCorpus().</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">hil_bill_corpus</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">VCorpus</span><span class="p">(</span><span class="n">VectorSource</span><span class="p">(</span><span class="n">bill_hillary_random</span><span class="o">$</span><span class="n">text</span><span class="p">))</span><span class="w"> </span><span class="c1">#Trammelsclass:</span><span class="w"> </span><span class="nf">class</span><span class="p">(</span><span class="n">hil_bill_corpus</span><span class="p">)</span><span class="w"> </span><span class="c1"># [1] "VCorpus" "Corpus"</span><span class="w"> </span></code></pre></div></div> <p>Think of the tm’s coprus object as a list. We can use the list operations to select documents in it and use inspect() with list operators to wangle text corpus elements.</p> <p>Next we create a document-term matrix via tm. A <a href="https://en.wikipedia.org/wiki/Document-term_matrix">document-term matrix</a> or term-document matrix is a mathematical matrix that describes the frequency of terms that occur in a hodgepodge of documents. In a document-term matrix, rows correspond to documents in the hodgepodge and columns correspond to terms. We combine it with vital cleaning operations, via functions tm provides, excluding a custom stopwords function. The DocumentTermMatrix() function helps us to unravel up the text documents into words:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># Stop-words (and, or ... you get the point)</span><span class="w"> </span><span class="n">stopwords2</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="k">function</span><span class="w"> </span><span class="p">(</span><span class="n">t</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="n">removeWords</span><span class="p">(</span><span class="n">t</span><span class="p">,</span><span class="w"> </span><span class="n">stopwords</span><span class="p">())}</span><span class="w"> </span><span class="c1"># test stopwords function:</span><span class="w"> </span><span class="n">stopwords2</span><span class="p">(</span><span class="s2">"He went here, and here, and here, or here"</span><span class="p">)</span><span class="w"> </span><span class="c1"># [1] "He went , , , "</span><span class="w"> </span><span class="c1"># DocumentTermMatrix</span><span class="w"> </span><span class="n">hil_bill_dtm</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">DocumentTermMatrix</span><span class="p">(</span><span class="n">hil_bill_corpus</span><span class="p">,</span><span class="w"> </span><span class="n">control</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">list</span><span class="p">(</span><span class="n">tolower</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="c1"># all lower case</span><span class="w"> </span><span class="n">removeNumbers</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="c1"># remove numbers</span><span class="w"> </span><span class="n">stopwords2</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="c1"># stopwords function</span><span class="w"> </span><span class="n">removePunctuation</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="c1"># remove .</span><span class="w"> </span><span class="n">stemming</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="c1"># Stemming reduces each word to its root from. Imagine you have words in the corpus such as "deported" or "deporting". Appliing the function would result in "deport" only, stripping the suffix (ed, ing, s ...).</span><span class="w"> </span><span class="n">stripWhitespace</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="w"> </span><span class="c1"># removes whitespaces or reduces them to only one each</span><span class="w"> </span><span class="p">))</span><span class="w"> </span><span class="n">hil_bill_dtm</span><span class="w"> </span><span class="n">Non</span><span class="o">-/</span><span class="n">sparse</span><span class="w"> </span><span class="n">entries</span><span class="o">:</span><span class="w"> </span><span class="m">94330</span><span class="o">/</span><span class="m">1356110</span><span class="w"> </span><span class="n">Sparsity</span><span class="w"> </span><span class="o">:</span><span class="w"> </span><span class="m">93</span><span class="o">%</span><span class="w"> </span><span class="n">Maximal</span><span class="w"> </span><span class="n">term</span><span class="w"> </span><span class="n">length</span><span class="o">:</span><span class="w"> </span><span class="m">45</span><span class="w"> </span><span class="n">Weighting</span><span class="w"> </span><span class="o">:</span><span class="w"> </span><span class="n">term</span><span class="w"> </span><span class="n">frequency</span><span class="w"> </span><span class="p">(</span><span class="n">tf</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>Lets split the data up into the training and test data, and save the outputs (“Bill” or “Hillary”) as a separate dataframe</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">hil_bill_dtm_train</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_bill_dtm</span><span class="p">[</span><span class="m">1</span><span class="o">:</span><span class="m">80</span><span class="p">,</span><span class="w"> </span><span class="p">]</span><span class="w"> </span><span class="n">hil_bill_dtm_test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_bill_dtm</span><span class="p">[</span><span class="m">81</span><span class="o">:</span><span class="m">135</span><span class="p">,</span><span class="w"> </span><span class="p">]</span><span class="w"> </span><span class="c1"># Actual output - whether it was Bill's or Hillary's speech </span><span class="w"> </span><span class="n">hil_bill_train_labels</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">bill_hillary_random</span><span class="p">[</span><span class="m">1</span><span class="o">:</span><span class="m">80</span><span class="p">,</span><span class="w"> </span><span class="p">]</span><span class="o">$</span><span class="n">type</span><span class="w"> </span><span class="n">hil_bill_test_labels</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">bill_hillary_random</span><span class="p">[</span><span class="m">81</span><span class="o">:</span><span class="m">135</span><span class="p">,</span><span class="w"> </span><span class="p">]</span><span class="o">$</span><span class="n">type</span><span class="w"> </span></code></pre></div></div> <p>Now we have all the data in a wipe form, permitting us to train our model. Lets visualise term frequencies via a wordcloud:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">RColorBrewer</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">wordcloud</span><span class="p">)</span><span class="w"> </span><span class="c1"># filter the data for a word cloud</span><span class="w"> </span><span class="n">hill</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">subset</span><span class="p">(</span><span class="n">bill_hillary_random</span><span class="p">,</span><span class="w"> </span><span class="n">type</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"Hillary"</span><span class="p">)</span><span class="w"> </span><span class="n">bill</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">subset</span><span class="p">(</span><span class="n">bill_hillary_random</span><span class="p">,</span><span class="w"> </span><span class="n">type</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"Bill"</span><span class="p">)</span><span class="w"> </span><span class="n">wordcloud</span><span class="p">(</span><span class="n">bill</span><span class="o">$</span><span class="n">text</span><span class="p">,</span><span class="w"> </span><span class="n">max.words</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">50</span><span class="p">,</span><span class="w"> </span><span class="n">scale</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="m">3</span><span class="p">,</span><span class="w"> </span><span class="m">0.5</span><span class="p">))</span><span class="w"> </span><span class="c1"># requite us 50 most worldwide words, you can do the same for Hillary's speeches</span><span class="w"> </span></code></pre></div></div> <p><img src="/images/naive/plots/bill_wordcloud.png" alt="alt text" /></p> <p>Classic Bill, he uses a set of disciplinary. For our model, we can reduce the number of words that are stuff taken into worth as features for the model to words that towards increasingly than a unrepealable value of times. Here we reducing it to at least 6 times. To do this, you can use the findFreqTerms() function by the tm package. Hereby we reduce the number of features lanugo to only the ones that are making a major difference to the probability numbering in our model. Our full-length set now consists of 1,674 features.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">hil_bill_freq_words</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">findFreqTerms</span><span class="p">(</span><span class="n">hil_bill_dtm_train</span><span class="p">,</span><span class="w"> </span><span class="m">12</span><span class="p">)</span><span class="w"> </span><span class="n">str</span><span class="p">(</span><span class="n">hil_bill_freq_words</span><span class="p">)</span><span class="w"> </span><span class="c1"># show the structure</span><span class="w"> </span><span class="n">chr</span><span class="w"> </span><span class="p">[</span><span class="m">1</span><span class="o">:</span><span class="m">1674</span><span class="p">]</span><span class="w"> </span><span class="s2">"abandon"</span><span class="w"> </span><span class="s2">"abil"</span><span class="w"> </span><span class="s2">"abl"</span><span class="w"> </span><span class="s2">"abov"</span><span class="w"> </span><span class="s2">"abroad"</span><span class="w"> </span><span class="s2">"absolut"</span><span class="w"> </span><span class="s2">"abus"</span><span class="w"> </span><span class="s2">"accept"</span><span class="w"> </span><span class="s2">"access"</span><span class="w"> </span><span class="s2">"accid"</span><span class="w"> </span><span class="s2">"accomplish"</span><span class="w"> </span><span class="n">...</span><span class="w"> </span></code></pre></div></div> <p>Now the DocumentTermMatrix’s features, the words in the text documents (each speech), needs to be filtered equal to the most frequent terms we just worked out via findFreqTerms(). We build a “convert” function to set well-defined features to “Hillary” in specimen it is her speech document we are dealing with, otherwise it’s Bill’s. Lastly we convert it when to a data-frame.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="w"> </span><span class="c1"># Filter most frequent terms seeming (for test and training data):</span><span class="w"> </span><span class="n">hil_bill_dtm_freq_train</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_bill_dtm_train</span><span class="p">[,</span><span class="w"> </span><span class="n">hil_bill_freq_words</span><span class="p">]</span><span class="w"> </span><span class="n">hil_bill_dtm_freq_test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_bill_dtm_test</span><span class="p">[,</span><span class="w"> </span><span class="n">hil_bill_freq_words</span><span class="p">]</span><span class="w"> </span><span class="c1"># the DTM needs to be filled now</span><span class="w"> </span><span class="n">convert_counts</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="k">function</span><span class="w"> </span><span class="p">(</span><span class="n">x</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">x</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">if_else</span><span class="p">(</span><span class="n">x</span><span class="w"> </span><span class="o">></span><span class="w"> </span><span class="m">0</span><span class="p">,</span><span class="w"> </span><span class="s2">"Hillary"</span><span class="p">,</span><span class="w"> </span><span class="s2">"Bill"</span><span class="p">)</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="c1">#Wieldconvert function to get categorial output values</span><span class="w"> </span><span class="n">hil_bill_train</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">apply</span><span class="p">(</span><span class="n">hil_bill_dtm_freq_train</span><span class="p">,</span><span class="w"> </span><span class="n">MARGIN</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">2</span><span class="p">,</span><span class="w"> </span><span class="n">convert_counts</span><span class="p">)</span><span class="w"> </span><span class="n">hil_bill_test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">apply</span><span class="p">(</span><span class="n">hil_bill_dtm_freq_test</span><span class="p">,</span><span class="w"> </span><span class="n">MARGIN</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">2</span><span class="p">,</span><span class="w"> </span><span class="n">convert_counts</span><span class="p">)</span><span class="w"> </span><span class="c1">#convert to df to see whats going on:</span><span class="w"> </span><span class="n">hil_bill_train_df</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">hil_bill_train</span><span class="p">)</span><span class="w"> </span><span class="n">View</span><span class="p">(</span><span class="n">hil_bill_train_df</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p><img src="/images/naive/plots/df.png" alt="alt text" /></p> <h1 id="training-the-model">Training the model</h1> <p>Lets train a model by using the <a href="https://cran.r-project.org/web/packages/e1071/index.html">package e1071</a> to wield the naiveBayes() function.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># Train the model:</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">e</span><span class="m">1071</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">gmodels</span><span class="p">)</span><span class="w"> </span><span class="n">hil_bill_classifier</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">naiveBayes</span><span class="p">(</span><span class="n">hil_bill_train</span><span class="p">,</span><span class="w"> </span><span class="n">hil_bill_train_labels</span><span class="p">,</span><span class="w"> </span><span class="n">laplace</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0</span><span class="p">)</span><span class="w"> </span><span class="c1"># we set the laplace factor to 0</span><span class="w"> </span></code></pre></div></div> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># Predict nomenclature with test data:</span><span class="w"> </span><span class="n">hil_bill_test_pred</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">predict</span><span class="p">(</span><span class="n">hil_bill_classifier</span><span class="p">,</span><span class="w"> </span><span class="n">hil_bill_test</span><span class="p">)</span><span class="w"> </span><span class="c1"># See how well model performed via a navigate table:</span><span class="w"> </span><span class="n">CrossTable</span><span class="p">(</span><span class="n">hil_bill_test_pred</span><span class="p">,</span><span class="w"> </span><span class="n">hil_bill_test_labels</span><span class="p">,</span><span class="w"> </span><span class="n">prop.chisq</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">prop.t</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">dnn</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="s2">"Predicted"</span><span class="p">,</span><span class="w"> </span><span class="s2">"Actual"</span><span class="p">))</span><span class="w"> </span></code></pre></div></div> <p><img src="/images/naive/plots/outcome_bill_hill.png" alt="alt text" /></p> <p>So whilom we did it.</p> <p>The table reveals that in total, 1 out of 55 were miss-classified, or 0.018% percent of the speeches (1 that were unquestionably Bills got miss-classified as Hillary’s, and 0 of Hillary’s got incorrectly classified as Bills). Naive Bayes is the standard for text classification.</p> <p>Is this vestige enough? Probably not, but it’s a start. It may have proven the point that Hillary is unique unbearable in her 2016 speeches, compared to her husband’s when in the 90ties. What well-nigh other’s? How well-nigh Obama. He is much closer on the topics Hillary has to deal with today, than Bill was when he ran for 42nd president of the United States.</p> <h1 id="obama-vs-hillary">Obama vs. Hillary:</h1> <p><img src="/images/naive/plots/o_h.jpeg" alt="alt text" /></p> <p>Lets try the same spiel with Obama’s speeches. We run the model on 107 of Hillary’s 2008 presidential wayfarers speeches and Hillary’s 96 2016 wayfarers speeches.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">Hillary</span><span class="w"> </span><span class="n">Obama</span><span class="w"> </span><span class="m">96</span><span class="w"> </span><span class="m">45</span><span class="w"> </span></code></pre></div></div> <p><img src="/images/naive/plots/outcome_obama.png" alt="alt text" /></p> <p>NB performs really well again, however not as well as before. With only a 4.87% of miss-classified instances, the model seems to be working reliably, and worldly-wise to filter Hillary’s speeches from Obama’s. So neither Obama has massively influenced her’s speaking style.</p> <h1 id="hillary-vs-her-former-self">Hillary vs. her former self:</h1> <p>We talked well-nigh time, and that is is a problem. While she might have lost the Democratic nomination to Barack Obama in 2008, she became Secretary of State. Leaving office without Obama’s first term, she undertook her own speaking engagements surpassing announcing her second presidential run in the 2016 election. So in theory, we should be worldly-wise to provide vestige whether or not there is a significant differences in her style when comparing speeches surpassing her speaking engagement tours and now after? Lets try and experiment with Hillary’s past.</p> <p>She successfully served as the 67th United States Secretary of State from 2009 to 2013. We will take her 2009 speeches and mix it with the ones for her current campaign.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">NLP</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">tm</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">e</span><span class="m">1071</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">dplyr</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">gmodels</span><span class="p">)</span><span class="w"> </span><span class="c1"># read in Clinton_2009 speeches (Info from the US state department), and wipe it:</span><span class="w"> </span><span class="n">regex</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="s2">"^.*:"</span><span class="w"> </span><span class="n">Clinton_2009</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read.csv</span><span class="p">(</span><span class="s2">"download/clinton_2009.csv"</span><span class="p">,</span><span class="w"> </span><span class="n">stringsAsFactors</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">)</span><span class="w"> </span><span class="n">View</span><span class="p">(</span><span class="n">Clinton_2009_fin</span><span class="p">)</span><span class="w"> </span><span class="n">Clinton_2009_fin</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">Clinton_2009</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">str_detect</span><span class="p">(</span><span class="n">years</span><span class="p">,</span><span class="w"> </span><span class="s2">"2009"</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">kind</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"Remarks"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">type</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Clinton_2009"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="o">-</span><span class="n">years</span><span class="p">,</span><span class="w"> </span><span class="o">-</span><span class="n">kind</span><span class="p">,</span><span class="w"> </span><span class="o">-</span><span class="n">title</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">text</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">str_replace_all</span><span class="p">(</span><span class="n">text</span><span class="p">,</span><span class="w"> </span><span class="s2">"SECRETARY CLINTON"</span><span class="p">,</span><span class="w"> </span><span class="s2">""</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">text</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">str_replace_all</span><span class="p">(</span><span class="n">text</span><span class="p">,</span><span class="w"> </span><span class="s2">"MODERATOR"</span><span class="p">,</span><span class="w"> </span><span class="s2">""</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">text</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">str_replace_all</span><span class="p">(</span><span class="n">text</span><span class="p">,</span><span class="w"> </span><span class="s2">"QUESTION"</span><span class="p">,</span><span class="w"> </span><span class="s2">""</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">text</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">str_replace_all</span><span class="p">(</span><span class="n">text</span><span class="p">,</span><span class="w"> </span><span class="s2">"^[^,]+\\s*"</span><span class="p">,</span><span class="w"> </span><span class="s2">""</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="c1"># use speech sample from the first comma onwards</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">nchar</span><span class="p">(</span><span class="n">text</span><span class="p">)</span><span class="w"> </span><span class="o">></span><span class="w"> </span><span class="m">10</span><span class="p">)</span><span class="w"> </span><span class="c1"># remove empty rows</span><span class="w"> </span><span class="n">final_clintons2</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">rbind</span><span class="p">(</span><span class="n">clinton</span><span class="p">,</span><span class="w"> </span><span class="n">Clinton_2009_fin</span><span class="p">)</span><span class="w"> </span><span class="c1"># combine the data with Hillary's speeches in the lawmaking previously</span><span class="w"> </span><span class="c1"># Randomize the sample:</span><span class="w"> </span><span class="n">set.seed</span><span class="p">(</span><span class="m">111</span><span class="p">)</span><span class="w"> </span><span class="c1"># set seed, to reproduce example</span><span class="w"> </span><span class="n">hil_old</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">sample_n</span><span class="p">(</span><span class="n">final_clintons2</span><span class="p">,</span><span class="w"> </span><span class="m">499</span><span class="p">)</span><span class="w"> </span><span class="n">hil_old</span><span class="o"><-</span><span class="w"> </span><span class="n">hil_old</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">type</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">factor</span><span class="p">(</span><span class="n">type</span><span class="p">))</span><span class="w"> </span><span class="n">table</span><span class="p">(</span><span class="n">hil_old</span><span class="o">$</span><span class="n">type</span><span class="p">)</span><span class="w"> </span><span class="c1"># we have 403 of clintons 2009 speeches, and scrutinizingly 100 of her current wayfarers speeches:</span><span class="w"> </span><span class="c1"># Clinton_2009 Hillary</span><span class="w"> </span><span class="c1"># 403 96</span><span class="w"> </span><span class="n">hil_old_corpus</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">VCorpus</span><span class="p">(</span><span class="n">VectorSource</span><span class="p">(</span><span class="n">hil_old</span><span class="o">$</span><span class="n">text</span><span class="p">))</span><span class="w"> </span><span class="c1"># wipe and DocumentTermMatrix:</span><span class="w"> </span><span class="n">hil_old_dtm</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">DocumentTermMatrix</span><span class="p">(</span><span class="n">hil_old_corpus</span><span class="p">,</span><span class="w"> </span><span class="n">control</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">list</span><span class="p">(</span><span class="n">tolower</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">removeNumbers</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">stopwords</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">removePunctuation</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">stemming</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">stripWhitespace</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="w"> </span><span class="p">))</span><span class="w"> </span><span class="n">hil_old_dtm_train</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_old_dtm</span><span class="p">[</span><span class="m">1</span><span class="o">:</span><span class="m">400</span><span class="p">,</span><span class="w"> </span><span class="p">]</span><span class="w"> </span><span class="n">hil_old_dtm_test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_old_dtm</span><span class="p">[</span><span class="m">401</span><span class="o">:</span><span class="m">499</span><span class="p">,</span><span class="w"> </span><span class="p">]</span><span class="w"> </span><span class="n">hil_old_train_labels</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_old</span><span class="p">[</span><span class="m">1</span><span class="o">:</span><span class="m">400</span><span class="p">,</span><span class="w"> </span><span class="p">]</span><span class="o">$</span><span class="n">type</span><span class="w"> </span><span class="n">hil_old_test_labels</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_old</span><span class="p">[</span><span class="m">401</span><span class="o">:</span><span class="m">499</span><span class="p">,</span><span class="w"> </span><span class="p">]</span><span class="o">$</span><span class="n">type</span><span class="w"> </span><span class="c1"># Model building:</span><span class="w"> </span><span class="n">hil_old_freq_words</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">findFreqTerms</span><span class="p">(</span><span class="n">hil_old_dtm_train</span><span class="p">,</span><span class="w"> </span><span class="m">5</span><span class="p">)</span><span class="w"> </span><span class="c1"># features restricted to an visitation of at least 5 times</span><span class="w"> </span><span class="n">convert_counds</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="k">function</span><span class="w"> </span><span class="p">(</span><span class="n">x</span><span class="p">)</span><span class="w"> </span><span class="p">{</span><span class="w"> </span><span class="n">x</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">if_else</span><span class="p">(</span><span class="n">x</span><span class="w"> </span><span class="o">></span><span class="w"> </span><span class="m">0</span><span class="p">,</span><span class="w"> </span><span class="s2">"Hillary_2016"</span><span class="p">,</span><span class="w"> </span><span class="s2">"Hillary_2009"</span><span class="p">)</span><span class="w"> </span><span class="p">}</span><span class="w"> </span><span class="n">hil_old_dtm_freq_train</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_old_dtm_train</span><span class="p">[,</span><span class="w"> </span><span class="n">hil_old_freq_words</span><span class="p">]</span><span class="w"> </span><span class="n">hil_old_dtm_freq_test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hil_old_dtm_test</span><span class="p">[,</span><span class="w"> </span><span class="n">hil_old_freq_words</span><span class="p">]</span><span class="w"> </span><span class="n">hil_old_train</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">apply</span><span class="p">(</span><span class="n">hil_old_dtm_freq_train</span><span class="p">,</span><span class="w"> </span><span class="n">MARGIN</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">2</span><span class="p">,</span><span class="w"> </span><span class="n">convert_counds</span><span class="p">)</span><span class="w"> </span><span class="n">hil_old_test</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">apply</span><span class="p">(</span><span class="n">hil_old_dtm_freq_test</span><span class="p">,</span><span class="w"> </span><span class="n">MARGIN</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">2</span><span class="p">,</span><span class="w"> </span><span class="n">convert_counds</span><span class="p">)</span><span class="w"> </span><span class="n">hil_old_classifier</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">naiveBayes</span><span class="p">(</span><span class="n">hil_old_train</span><span class="p">,</span><span class="w"> </span><span class="n">hil_old_train_labels</span><span class="p">,</span><span class="w"> </span><span class="n">laplace</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0</span><span class="p">)</span><span class="w"> </span><span class="n">str</span><span class="p">(</span><span class="n">hil_bill_classifier</span><span class="p">)</span><span class="w"> </span><span class="n">hil_old_test_pred</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">predict</span><span class="p">(</span><span class="n">hil_old_classifier</span><span class="p">,</span><span class="w"> </span><span class="n">hil_old_test</span><span class="p">)</span><span class="w"> </span><span class="n">CrossTable</span><span class="p">(</span><span class="n">hil_old_test_pred</span><span class="p">,</span><span class="w"> </span><span class="n">hil_old_test_labels</span><span class="p">,</span><span class="w"> </span><span class="n">prop.chisq</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">prop.t</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">dnn</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="s2">"Predicted"</span><span class="p">,</span><span class="w"> </span><span class="s2">"Actual"</span><span class="p">))</span><span class="w"> </span></code></pre></div></div> <p><img src="/images/naive/plots/outcome_oldHill_hill.png" alt="alt text" /></p> <p>What we see, despite showing somewhat of the same terms (word-clouds below), the model guessed incorrectly in only well-nigh 5% of the cases, where Clinton’s 2009 remarks got miss-classified as 2016 speeches.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">hill</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">subset</span><span class="p">(</span><span class="n">hil_old</span><span class="p">,</span><span class="w"> </span><span class="n">type</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"Hillary"</span><span class="p">)</span><span class="w"> </span><span class="n">Old_Hillary</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">subset</span><span class="p">(</span><span class="n">hil_old</span><span class="p">,</span><span class="w"> </span><span class="n">type</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"Old_Hillary"</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">RColorBrewer</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">wordcloud</span><span class="p">)</span><span class="w"> </span><span class="n">wordcloud</span><span class="p">(</span><span class="n">hill</span><span class="o">$</span><span class="n">text</span><span class="p">,</span><span class="w"> </span><span class="n">max.words</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">30</span><span class="p">,</span><span class="w"> </span><span class="n">scal</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="m">3</span><span class="p">,</span><span class="w"> </span><span class="m">0.2</span><span class="p">))</span><span class="w"> </span><span class="n">wordcloud</span><span class="p">(</span><span class="n">Old_Hillary</span><span class="o">$</span><span class="n">text</span><span class="p">,</span><span class="w"> </span><span class="n">max.words</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">30</span><span class="p">,</span><span class="w"> </span><span class="n">scale</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="m">3</span><span class="p">,</span><span class="w"> </span><span class="m">0.5</span><span class="p">))</span><span class="w"> </span></code></pre></div></div> <h2 id="classifying-hillarys-presidential-speeches-2008-vs-2016">Classifying Hillary’s presidential speeches (2008 vs. 2016)</h2> <p><img src="/images/naive/plots/oldHill_wordcloud.png" alt="alt text" /></p> <p>The speeches as Secretary of State might not be perfect to judge on her wayfarers speaking style for the 2016 presidential election. To find a possibly increasingly closely related dataset, Hillary’s presidential wayfarers speeches from her 2008 presidential referendum wayfarers might serve us well. Again, fetched data from the web, this time from the <a href="http://www.presidency.ucsb.edu/2008_election_speeches.php?candidate=70&campaign=2008CLINTON&doctype=5000">UCSB page</a> . We see our model in whoopee on the pursuit instances:</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">Clinton_2008_Presidential_Election</span><span class="w"> </span><span class="n">Hillary_2016</span><span class="w"> </span><span class="m">107</span><span class="w"> </span><span class="m">96</span><span class="w"> </span></code></pre></div></div> <p><img src="/images/naive/plots/outcome_oldHill_presidential_08_hill.png" alt="alt text" /> Remarkable! Our NB model, with an verism of 98%, performed really well and was worldly-wise to spot the differences between Clinton’s 2016 wayfarers and her wayfarers speeches she gave in 2007 and 2008. This could mean, that there is a significant difference between her speaking style and the topics she talks about, when comparing 2008 with 2016 wayfarers rally speeches.</p> <h1 id="running-the-nb-against-hillarys-tweets">Running the NB versus Hillary’s tweets:</h1> <p>David Robinson has washed-up it and <a href="http://varianceexplained.org/r/trump-tweets/">found</a> Trump’s uniqueness in his social media feed. We are looking at something similar for Hillary’s tweets.</p> <p>In order to run a NB model versus her tweets, we need text that Hillary didn’t write (as a training set). Her wayfarers blog may be a good start. I have written a scraper to get the last 100 blog entries. The data will be trained on 89 blog entries (cleaned up, so we don’t include Spanish entries here), and Hillary’s speeches of her 2016 wayfarers got included then representative for her own style. When we sort out the tweet messages that Hillary signs with an “-H” or “-Hillary”, we know they are hers (several people have reported in it, which we want to trust). With this in mind, we build a new model (as above). We take her blog posts, and her speeches, and train a NB model. Next, we build a test set with her tweets, and nail labels for the ones Hillary signed.</p> <h2 id="classification-on-tweet-text-set">Classification on tweet text set</h2> <p>We run our classifier on the tweets and notice that our model got it completely wrong. How sad :-(</p> <p><img src="/images/naive/plots/output_tweets.png" alt="alt text" /></p> <p>This could midpoint many things, including that the test data wasn’t properly cleaned. 47% were prescribed to a wrong label, times when the model unsupportable that Hillary written the tweet herself, while for eight tweets by Hillary, the classifier reckoned that it was Clinton’s team who wrote it.</p> <p><img src="/images/naive/giphy.gif" alt="alt text" /></p> <h1 id="conclusion">Conclusion:</h1> <p>Here is an overview on how well the model performed on various speakers and texts:</p> <p><img src="/images/naive/plots/conclusion.jpg" alt="alt text" /> Overall, Naive Bayes for text - in our specimen speech - nomenclature is a powerful tool and works reliable in wipe data. To judge how unique a person’s speaking style is works as long it is not stuff mixed up with written text data. Speeches are variegated from copy, and one doesn’t writes as one speaks. For Hillary’s tweets, this little experiment did not work.</p> <p>However, our models could establish some vestige that showed that she is indeed her own persona. Her speeches may or may not reflect her own beliefs but certainly her own speaking style (and not her husband’s or other people she worked with in the past, such as Barack Obama). Her wayfarers is her unique voice, unique plane in the sense of her past presidential rally in 2008.</p> <p><img src="/images/naive/giphy2.gif" alt="alt text" /></p>Ben Heubltechjournalism@gmail.comHow unique is Hillary Clinton’s style? What does her speeches tell us well-nigh her uniqueness? In this post I built several Naive Bayes models, trained them on Hillary’s 2016 wayfarers speeches and unromantic them on other remarks, tweets and text corpuses. The results is Interesting, and presents flipside journalistic use-case for machine learning.Hillary Clinton and her strategy to speak2016-09-20T00:00:00+00:002016-09-20T00:00:00+00:00https://benheubl.github.io/data%20analysis/strategy-to-speak<p><strong>Text wringer in R on speeches is one way to find some new untold stories in the presidential referendum discussion. In this post we will concentrate on Hillary Clinton and her strategy to speak</strong></p> <p><img src="/images/strategy-to-speak/header2.png" alt="alt text" /></p> <h1 id="im-in-and-im-in-to-win-2008-vs-2016">“I’m in, and I’m in to win: 2008 vs. 2016</h1> <p>To compare Clinton’s potential candidacy in 2008 with her current one, we will scrape speech data from both campaigns. Her 2016 speeches are misogynist on Hillary’s wayfarers website, while speeches delivered 2007 and 2008 are to be found <a href="http://www.presidency.ucsb.edu/2008_election_speeches.php?candidate=70&campaign=2008CLINTON&doctype=5000">here</a>.</p> <p><img src="/images/strategy-to-speak/plots/2008_speech_lines.jpg" alt="alt text" /> To end up with a relative reliable sentiment line, we will use the <a href="https://cran.r-project.org/web/packages/tidytext/index.html">tidytext package</a>, by David Robinson and Julia Silge. Both made a unconfined effort to explain examples on their blogs (<a href="http://juliasilge.com/blog/">Julia Silge</a>, <a href="http://varianceexplained.org/">David Robinson</a>).</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">tidytext</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">tidyr</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">ggplot2</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">viridis</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">grid</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">directlabels</span><span class="p">)</span><span class="w"> </span><span class="n">nullacht_speeches</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">pr_2008_clean</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">linenumber</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">row_number</span><span class="p">())</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">text</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">as.character</span><span class="p">(</span><span class="n">text</span><span class="p">))</span><span class="w"> </span><span class="n">tidy_nullacht_speeches</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">nullacht_speeches</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">unnest_tokens</span><span class="p">(</span><span class="n">sentences</span><span class="p">,</span><span class="w"> </span><span class="n">text</span><span class="p">,</span><span class="w"> </span><span class="n">token</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"sentences"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">speech_08</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">row_number</span><span class="p">())</span><span class="w"> </span><span class="n">tidy_nullacht_speeches</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">tidy_nullacht_speeches</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">unnest_tokens</span><span class="p">(</span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">sentences</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">speech_08</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">linenumber_word</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">row_number</span><span class="p">())</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">numberWords</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">n</span><span class="p">())</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">ungroup</span><span class="p">()</span><span class="w"> </span><span class="c1"># do increasingly cleaning</span><span class="w"> </span><span class="n">data</span><span class="p">(</span><span class="s2">"stop_words"</span><span class="p">)</span><span class="w"> </span><span class="n">tidy_nullacht_speeches</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">tidy_nullacht_speeches</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">anti_join</span><span class="p">(</span><span class="n">stop_words</span><span class="p">)</span><span class="w"> </span><span class="c1"># remove all the stop words</span><span class="w"> </span><span class="c1"># counts words</span><span class="w"> </span><span class="n">tidy_nullacht_speeches</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">count</span><span class="p">(</span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">sort</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="kc">TRUE</span><span class="p">)</span><span class="w"> </span><span class="c1"># load sentiment lexicon</span><span class="w"> </span><span class="n">bing</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">sentiments</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">lexicon</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"bing"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="o">-</span><span class="n">score</span><span class="p">)</span><span class="w"> </span><span class="c1">#Summatesentiment score</span><span class="w"> </span><span class="n">All_sentiment_All</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">tidy_nullacht_speeches</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">inner_join</span><span class="p">(</span><span class="n">bing</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">count</span><span class="p">(</span><span class="n">Dates</span><span class="p">,</span><span class="w"> </span><span class="n">numberWords</span><span class="p">,</span><span class="w"> </span><span class="n">index_word</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">linenumber_word</span><span class="w"> </span><span class="o">%/%</span><span class="w"> </span><span class="m">1</span><span class="p">,</span><span class="w"> </span><span class="n">sentiment</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">spread</span><span class="p">(</span><span class="n">sentiment</span><span class="p">,</span><span class="w"> </span><span class="n">n</span><span class="p">,</span><span class="w"> </span><span class="n">fill</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">sentiment</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">positive</span><span class="w"> </span><span class="o">-</span><span class="w"> </span><span class="n">negative</span><span class="p">)</span><span class="w"> </span><span class="n">All_sentiment_standard_All</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">All_sentiment_All</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">Dates</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">Overall_sentiment</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">sum</span><span class="p">(</span><span class="n">sentiment</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">max</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">max</span><span class="p">(</span><span class="n">index_word</span><span class="p">))</span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">min</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">1</span><span class="p">)</span><span class="o">%>%</span><span class="w"> </span><span class="n">ungroup</span><span class="p">()</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">index_stan</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="p">(</span><span class="m">100</span><span class="o">*</span><span class="n">index_word</span><span class="p">)</span><span class="o">/</span><span class="n">max</span><span class="p">)</span><span class="w"> </span><span class="c1"># Plotting:</span><span class="w"> </span><span class="n">ggplot</span><span class="p">(</span><span class="n">All_sentiment_standard_All</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">index_stan</span><span class="p">,</span><span class="w"> </span><span class="n">sentiment</span><span class="p">,</span><span class="w"> </span><span class="n">label</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">Dates</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme_bw</span><span class="p">()</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="c1">#geom_jitter(height = 0.4, show.legend = F, start = 0.1) +</span><span class="w"> </span><span class="n">ggtitle</span><span class="p">(</span><span class="s2">"Hillary's 2008 presidential referendum speeches"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_line</span><span class="p">(</span><span class="n">stat</span><span class="o">=</span><span class="s2">"smooth"</span><span class="p">,</span><span class="n">method</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"loess"</span><span class="p">,</span><span class="w"> </span><span class="n">size</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.3</span><span class="p">,</span><span class="w"> </span><span class="n">show.legend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">alpha</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.1</span><span class="p">,</span><span class="w"> </span><span class="n">group</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">Dates</span><span class="p">,</span><span class="w"> </span><span class="n">col</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">sent</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">scale_colour_gradient</span><span class="p">(</span><span class="n">limits</span><span class="o">=</span><span class="nf">c</span><span class="p">(</span><span class="m">-63</span><span class="p">,</span><span class="w"> </span><span class="m">83</span><span class="p">),</span><span class="w"> </span><span class="n">low</span><span class="o">=</span><span class="s2">"navy blue"</span><span class="p">,</span><span class="w"> </span><span class="n">high</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"red"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_smooth</span><span class="p">(</span><span class="n">method</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"loess"</span><span class="p">,</span><span class="w"> </span><span class="n">show.legend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">size</span><span class="w"> </span><span class="o">=</span><span class="m">2</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">xlab</span><span class="p">(</span><span class="s2">"Standardized sentence index"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ylab</span><span class="p">(</span><span class="s2">"Sentiment (+/-)"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ylim</span><span class="p">(</span><span class="m">-2</span><span class="p">,</span><span class="w"> </span><span class="m">2</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>Now we can add moreover the individual sentence scores to the picture. We can do the same for her 2016 speeches and you may notice a difference:</p> <p><img src="/images/strategy-to-speak/plots/2008_speech_points.jpg" alt="alt text" /></p> <p>Here the same plot on Hillary’s 2016 speeches:</p> <p><img src="/images/strategy-to-speak/plots/20016_speech.jpg" alt="alt text" /></p> <p>The dots represent the sentiment scores for each sentence in all of her speeches for that year. The red lines represent a weighted stereotype line, one for each of Hillary’s speeches. We can see that the distribution of the dots are slightly increasingly spread out for 2016. The difference of the spread of the woebegone dots tells us that Hilary Clinton may have made increasingly use of increasingly judgemental verbs and nouns in sentences in 2016 than in her 2008 campaign, while her overall sentiment wideness speeches remained relatively balanced.</p> <h1 id="convention-speeches">Convention speeches:</h1> <p><img src="/images/strategy-to-speak/hillary2.jpg" alt="alt text" />Withoutthe conventions, it became well-spoken Clinton will go versus Trump in the referendum finals.Olderwe learned that Clinton is often well-turned in her sentiment. Listeners to the institute speeches noted how negative Trump’s speech was compared to others. Similar to her wayfarers speeches, Clinton’s speech at the 2016 institute was often considered to be rather balanced, except when she discussed how unfit her opponent Trump is for presidency.</p> <p>To measure sentiment in institute speeches, we use <a href="https://www.r-bloggers.com/the-life-changing-magic-of-tidying-text/">Julia Silge’s and David Robinson’s tidytext</a> package again. First we load moreover dplyr and stringr for some vital data wrangling.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">tidytext</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">dplyr</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">stringr</span><span class="p">)</span><span class="w"> </span><span class="n">Speeches.19_clean_Democrats</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">Speeches.19_clean</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">party</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"Democratic"</span><span class="p">)</span><span class="w"> </span><span class="n">Speeches.19_clean_Republican</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">Speeches.19_clean</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">party</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"Republican"</span><span class="p">)</span><span class="w"> </span><span class="n">conv.all_Dem</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">Speeches.19_clean_Democrats</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">title</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">linenumber</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">row_number</span><span class="p">())</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">ungroup</span><span class="p">()</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">separate</span><span class="p">(</span><span class="n">title</span><span class="p">,</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="s2">"speaker"</span><span class="p">,</span><span class="w"> </span><span class="s2">"Years"</span><span class="p">),</span><span class="w"> </span><span class="n">sep</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"_"</span><span class="p">,</span><span class="w"> </span><span class="n">remove</span><span class="o">=</span><span class="kc">FALSE</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>The next thing is to unnest the text into words. We moreover load in stop words and use dplyr’s “anti-join” to wipe the data from filler words and subordinating conjunctions.Flipsidething we unify is to involve the bing lexicon dataset. It will indulge us to express each word’s sentiment.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">tidy_All_Dem</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">conv.all_Dem</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">unnest_tokens</span><span class="p">(</span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">text</span><span class="p">)</span><span class="w"> </span><span class="n">data</span><span class="p">(</span><span class="s2">"stop_words"</span><span class="p">)</span><span class="w"> </span><span class="n">tidy_All_Dem</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">tidy_All_Dem</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">anti_join</span><span class="p">(</span><span class="n">stop_words</span><span class="p">)</span><span class="w"> </span><span class="n">tidy_All_Dem</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">count</span><span class="p">(</span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">sort</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="kc">TRUE</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">tidyr</span><span class="p">)</span><span class="w"> </span><span class="n">bing</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">sentiments</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">lexicon</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="s2">"bing"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="o">-</span><span class="n">score</span><span class="p">)</span><span class="w"> </span><span class="n">All_sentiment_Dem</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">tidy_All_Dem</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">inner_join</span><span class="p">(</span><span class="n">bing</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">count</span><span class="p">(</span><span class="n">title</span><span class="p">,</span><span class="w"> </span><span class="n">index</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">linenumber</span><span class="w"> </span><span class="o">%/%</span><span class="w"> </span><span class="m">1</span><span class="p">,</span><span class="w"> </span><span class="n">sentiment</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">spread</span><span class="p">(</span><span class="n">sentiment</span><span class="p">,</span><span class="w"> </span><span class="n">n</span><span class="p">,</span><span class="w"> </span><span class="n">fill</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">sentiment</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">positive</span><span class="w"> </span><span class="o">-</span><span class="w"> </span><span class="n">negative</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">separate</span><span class="p">(</span><span class="n">title</span><span class="p">,</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="s2">"speaker"</span><span class="p">,</span><span class="w"> </span><span class="s2">"Years"</span><span class="p">),</span><span class="w"> </span><span class="n">sep</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"_"</span><span class="p">,</span><span class="w"> </span><span class="n">remove</span><span class="o">=</span><span class="kc">FALSE</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>Now we are good to go to plot. We use ggplot’s facet_wrap() function and a weighted LOESS line and n set to 50.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">ggplot2</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">viridis</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">grid</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">directlabels</span><span class="p">)</span><span class="w"> </span><span class="n">All_sentiment_standard_Dem</span><span class="o">$</span><span class="n">title</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">factor</span><span class="p">(</span><span class="n">All_sentiment_standard_Dem</span><span class="o">$</span><span class="n">title</span><span class="p">,</span><span class="w"> </span><span class="n">levels</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="p">(</span><span class="n">All_sentiment_standard_Dem</span><span class="o">$</span><span class="n">title</span><span class="p">[</span><span class="n">order</span><span class="p">(</span><span class="n">All_sentiment_standard_Dem</span><span class="o">$</span><span class="n">Years</span><span class="p">)]))</span><span class="w"> </span><span class="n">ggplot</span><span class="p">(</span><span class="n">All_sentiment_standard_Dem</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">index_stan</span><span class="p">,</span><span class="w"> </span><span class="n">sentiment</span><span class="p">,</span><span class="w"> </span><span class="n">group</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">title</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">scale_colour_brewer</span><span class="p">(</span><span class="n">palette</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Set1"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_path</span><span class="p">(</span><span class="n">show.legend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">alpha</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.3</span><span class="p">,</span><span class="w"> </span><span class="n">linejoin</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"mitre"</span><span class="p">,</span><span class="w"> </span><span class="n">lineend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"butt"</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">col</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">if_else</span><span class="p">(</span><span class="n">hillaryClinton_line</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="m">0</span><span class="p">,</span><span class="w"> </span><span class="s2">"red"</span><span class="p">,</span><span class="w"> </span><span class="s2">"grey"</span><span class="p">)))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">facet_wrap</span><span class="p">(</span><span class="n">Years</span><span class="o">~</span><span class="n">speaker</span><span class="p">,</span><span class="w"> </span><span class="n">nrow</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">2</span><span class="p">,</span><span class="w"> </span><span class="n">scales</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"free_x"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme_minimal</span><span class="p">(</span><span class="n">base_size</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">13</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">labs</span><span class="p">(</span><span class="n">title</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Sentiment in democratic US presidential candidates institute speeches"</span><span class="p">,</span><span class="w"> </span><span class="n">y</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Sentiment"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_smooth</span><span class="p">(</span><span class="n">method</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"loess"</span><span class="p">,</span><span class="w"> </span><span class="n">n</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">50</span><span class="p">,</span><span class="w"> </span><span class="n">show.legend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">col</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">if_else</span><span class="p">(</span><span class="n">hillaryClinton_line</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="m">0</span><span class="p">,</span><span class="w"> </span><span class="s2">"red"</span><span class="p">,</span><span class="w"> </span><span class="s2">"grey"</span><span class="p">)))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">scale_fill_viridis</span><span class="p">(</span><span class="n">end</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.75</span><span class="p">,</span><span class="w"> </span><span class="n">discrete</span><span class="o">=</span><span class="kc">TRUE</span><span class="p">,</span><span class="w"> </span><span class="n">direction</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">-1</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">scale_x_discrete</span><span class="p">(</span><span class="n">expand</span><span class="o">=</span><span class="nf">c</span><span class="p">(</span><span class="m">0.02</span><span class="p">,</span><span class="m">0</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme</span><span class="p">(</span><span class="n">strip.text</span><span class="o">=</span><span class="n">element_text</span><span class="p">(</span><span class="n">hjust</span><span class="o">=</span><span class="m">0</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme</span><span class="p">(</span><span class="n">strip.text</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">element_text</span><span class="p">(</span><span class="n">face</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"italic"</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme</span><span class="p">(</span><span class="n">axis.title.x</span><span class="o">=</span><span class="n">element_blank</span><span class="p">())</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme</span><span class="p">(</span><span class="n">axis.ticks.x</span><span class="o">=</span><span class="n">element_blank</span><span class="p">())</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme</span><span class="p">(</span><span class="n">axis.text.x</span><span class="o">=</span><span class="n">element_blank</span><span class="p">())</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_dl</span><span class="p">(</span><span class="n">aes</span><span class="p">(</span><span class="n">label</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">toupper</span><span class="p">(</span><span class="n">Years</span><span class="p">)),</span><span class="w"> </span><span class="n">method</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">list</span><span class="p">(</span><span class="n">dl.trans</span><span class="p">(</span><span class="n">x</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">x</span><span class="w"> </span><span class="o">-</span><span class="w"> </span><span class="m">1.3</span><span class="p">),</span><span class="w"> </span><span class="s2">"last.points"</span><span class="p">,</span><span class="w"> </span><span class="n">cex</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.5</span><span class="p">))</span><span class="w"> </span></code></pre></div></div> <p><img src="https://benheubl.github.io/images/strategy-to-speak/plots/conventionsHillary.svg" alt="pic1" /></p> <blockquote> <p>The plot shows the sentiment wringer for democrate institute speeches over the past years. A undecorous weighted loess line is introduced that shows a unstipulated trend over the undertow of each speech.UnmistakablyHillary’s speech is rather balanced. We can do the same thing for the republican institute speeches and witness one of the most negative talks over the past decades by candidate Trump.</p> </blockquote> <p><img src="https://benheubl.github.io/images/strategy-to-speak/plots/conventionsTrump.svg" alt="pic1" /></p> <blockquote> <p>Length: Over the past three decades, institute speeches significantly varied in their length and while Bill Clinton’s institute speech listeners in 1996 must have a nonflexible time to stand his 7,000 words, other candidates such as Mondale kept it unenduring lanugo to 2400.</p> </blockquote> <h1 id="hillarys-speeches-as-secretary-of-state">Hillary’s speeches as Secretary of State</h1> <p>We could moreover delve into Hillary’s past. As it was easy to find <a href="http://www.state.gov/secretary/20092013clinton/rm/index.htm">her remarks</a> from her time when she served as US Secretary of State from 2009 to 2013, we can do a similar meta sentiment wringer for her Secretary of State speeches. The undecorous lines stand for the sentiment wideness speeches, and gives an overall sense of a sentiment level wideness the years, the larger undecorous circles represent speeches that featured the word “women” in the remark’s title. Hillary kept a positive wastefulness wideness those years.</p> <p><img src="https://benheubl.github.io/images/strategy-to-speak/plots/women_secretary.jpg" alt="pic1" /></p> <blockquote> <p>Looking only at Hillary’s remarks at the US state department from 2009 to 2013, she gave a lot increasingly speeches in her first year as Secretary of State. Clinton is knows for stuff a women’s right activist. It is not surprising that the word “Women” was part of many speeches she gave as Secretary of State.</p> </blockquote> <h1 id="what-are-hillarys-2016-campaign-speeches-all-about">What are Hillary’s 2016 wayfarers speeches all about?</h1> <p>We want to find out the cadre topics Hillary Clinton spoke well-nigh in her wayfarers speeches. For this, we will use the tidytext function bind_tf_idf(). From our scraping activity, we received 96 speeches from Hillary’s 2016 wayfarers website. Let’s tidy up the dataset first, and then perform a term-frequency-inverse-document-frequency (ft-idf) wringer on the text corpus.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">dplyr</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">tidytext</span><span class="p">)</span><span class="w"> </span><span class="c1"># read in the data:</span><span class="w"> </span><span class="n">pr_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">read.csv</span><span class="p">(</span><span class="s2">"clinton_2016.csv"</span><span class="p">,</span><span class="w"> </span><span class="n">header</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">stringsAsFactors</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">)</span><span class="w"> </span><span class="n">pr_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">pr_2016</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">wann</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">group_speech</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">n</span><span class="p">())</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">ungroup</span><span class="p">()</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">select</span><span class="p">(</span><span class="o">-</span><span class="n">X</span><span class="p">)</span><span class="w"> </span><span class="n">speeches_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">pr_2016</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">wann</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">unnest_tokens</span><span class="p">(</span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">speech1</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">count</span><span class="p">(</span><span class="n">wann</span><span class="p">,</span><span class="w"> </span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">sort</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">)</span><span class="w"> </span><span class="n">speeches_2016_total</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">speeches_2016</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">wann</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="n">summarise</span><span class="p">(</span><span class="n">all_speeches</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">sum</span><span class="p">(</span><span class="n">n</span><span class="p">))</span><span class="w"> </span><span class="n">speeches_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">left_join</span><span class="p">(</span><span class="n">speeches_2016</span><span class="p">,</span><span class="w"> </span><span class="n">speeches_2016_total</span><span class="p">)</span><span class="w"> </span><span class="n">speeches_2016</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">speeches_2016</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">bind_tf_idf</span><span class="p">(</span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">wann</span><span class="p">,</span><span class="w"> </span><span class="n">n</span><span class="p">)</span><span class="w"> </span><span class="c1">## Plotting the highest frequency for each speech over time:</span><span class="w"> </span><span class="n">speeches_2016_termFr_plot</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">speeches_2016</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">wann</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">tf_idf</span><span class="w"> </span><span class="o">==</span><span class="w"> </span><span class="nf">max</span><span class="p">(</span><span class="n">tf_idf</span><span class="p">))</span><span class="w"> </span><span class="n">speeches_2016_termFr_plot_dates</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">speeches_2016_termFr_plot</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">dates</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">as.Date</span><span class="p">(</span><span class="nf">as.character</span><span class="p">(</span><span class="n">wann</span><span class="p">),</span><span class="w"> </span><span class="s2">"%B%d,%Y"</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">dates</span><span class="w"> </span><span class="o">!=</span><span class="w"> </span><span class="s2">"2015-05-19"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">all_speeches</span><span class="w"> </span><span class="o"><</span><span class="w"> </span><span class="m">50000</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">mutate</span><span class="p">(</span><span class="n">word</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">toupper</span><span class="p">(</span><span class="n">word</span><span class="p">))</span><span class="w"> </span><span class="n">ggplot</span><span class="p">(</span><span class="n">speeches_2016_termFr_plot_dates</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">dates</span><span class="p">,</span><span class="w"> </span><span class="n">all_speeches</span><span class="p">,</span><span class="w"> </span><span class="n">label</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">word</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_point</span><span class="p">(</span><span class="n">alpha</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.5</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_line</span><span class="p">(</span><span class="n">alpha</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.1</span><span class="p">,</span><span class="w"> </span><span class="n">size</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">3</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme_bw</span><span class="p">()</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ggtitle</span><span class="p">(</span><span class="s2">"TF IDF wringer of Hillary Clinton speeches, 2016"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_text</span><span class="p">(</span><span class="n">check_overlap</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">size</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">3</span><span class="p">,</span><span class="w"> </span><span class="n">nudge_x</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">6</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">label</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">word</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ylab</span><span class="p">(</span><span class="s2">"Number of words in speech"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">xlab</span><span class="p">(</span><span class="s2">"2016, dates"</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p><img src="https://benheubl.github.io/images/strategy-to-speak/plots/plot_speeches_tf_idf_2.jpg" alt="pic1" /></p> <p>In this chart, we can visualize <a href="https://en.wikipedia.org/wiki/Tf%E2%80%93idf">TF-IDF</a> Hillary’s speeches over time. The Y turning shows the number of words the term appeared in a speech relative to the overall number of words in each speech. The X turning represents dates the speeches were given (according to Hillary’s wayfarers blog). The line gives you an idea of the most frequent terms calculated versus the most frequent terms wideness the unshortened set of speeches. It gives us a relatively good understanding of the topics she talked most commonly about, and how this reverted over the undertow of the presidential-rally.</p> <p>To make things increasingly interesting, we can compare it to the number of occasions for each speech when she mentioned “Trump” (also measured in term frequency). In speeches, Trump’s name was mentioned withal “Court”, “California”, and “Police”.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">ggplot</span><span class="p">(</span><span class="n">speeches_2016_termFr_plot_dates</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">dates</span><span class="p">,</span><span class="w"> </span><span class="n">tf</span><span class="p">,</span><span class="w"> </span><span class="n">label</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">word</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_point</span><span class="p">(</span><span class="n">alpha</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.5</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_line</span><span class="p">(</span><span class="n">alpha</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.1</span><span class="p">,</span><span class="w"> </span><span class="n">size</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">3</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">col</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"tf"</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme_bw</span><span class="p">()</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ggtitle</span><span class="p">(</span><span class="s2">"TF IDF wringer of Hillary Clinton speeches, 2016"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_text</span><span class="p">(</span><span class="n">check_overlap</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">size</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">3</span><span class="p">,</span><span class="w"> </span><span class="n">nudge_x</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">6</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">label</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">word</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ylab</span><span class="p">(</span><span class="s2">"The number of times this word appears in the speech"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">xlab</span><span class="p">(</span><span class="s2">"2016, dates"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_line</span><span class="p">(</span><span class="n">inherit.aes</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">alpha</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.1</span><span class="p">,</span><span class="w"> </span><span class="n">size</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">3</span><span class="p">,</span><span class="w"> </span><span class="n">data</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">speeches_2016_termFr_plot_trump_dates</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">dates</span><span class="p">,</span><span class="w"> </span><span class="n">tf</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_point</span><span class="p">(</span><span class="n">inherit.aes</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">data</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">speeches_2016_termFr_plot_trump_dates</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">dates</span><span class="p">,</span><span class="w"> </span><span class="n">tf</span><span class="p">,</span><span class="w"> </span><span class="n">color</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Trump mentioned"</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">scale_colour_brewer</span><span class="p">(</span><span class="n">palette</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Set1"</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p><img src="https://benheubl.github.io/images/strategy-to-speak/plots/Rplot02.jpeg" alt="pic1" /></p> <p>Trump’s name fell increasingly over the past months, possibly a strategic wordplay to Trump’s verbal assaults in his hate speeches. She must have mentioned and attacked him increasingly heavily moreover in the undertow of his increasing chances of winning.</p> <h1 id="who-is-hillarys-speeches-most-aligned-with">Who is Hillary’s speeches most aligned with?</h1> <p>Politicians have their own style of course, but could we find out how her word frequencies differ to other member of the political family. Comparing Hillary’s speeches with wayfarers speeches by Barack Obama in 2012, we understand that both aren’t pretty well aligned. If aligned, the orchestration would squint different. The dots would cluster increasingly heavily virtually undecorous line and be less spread out to the X and Y dimensions.</p> <p><img src="https://benheubl.github.io/images/strategy-to-speak/plots/plot_speeches_Obama_vs_hillary.jpg" alt="pic1" /></p> <p>If we do it for Trump’s wayfarers speeches, there is plane a wider spread. This comes at no surprise. Both political figures have a very unshared speaking style.</p> <p><img src="https://benheubl.github.io/images/strategy-to-speak/plots/Rplot04.jpeg" alt="pic1" /></p> <h1 id="unsupervised-learning-clustering-hillarys-2016-campaign-speeches">Unsupervised learning: clustering Hillary’s 2016 wayfarers speeches</h1> <p>Clustering is an unsupervised machine learning task, helping with automatically dividing our speech data into topic clusters. The aim of this exercise is to find the natural grouping of the speeches, which we will try to label later. We have seen that Hillary discussed varies topics, including childcare, the police and veterans. Without remoter knowledge of what comprises a speech cluster, how can a computer know where one group ends and flipside begins? The wordplay lies in the concept of similarity.</p> <p>The first step is to tokenize our document again, using the wonderful tidytext package. Each document is a stage the speech, or multiple speeches were delivered (in the data we find dates that full-length multiple speeches).</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">dplyr</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">tidytext</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">stringr</span><span class="p">)</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">tidyr</span><span class="p">)</span><span class="w"> </span><span class="n">speeches_2016_unnest_tokens</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">speeches_2016_correlation</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">tidytext</span><span class="o">::</span><span class="n">unnest_tokens</span><span class="p">(</span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">text</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">anti_join</span><span class="p">(</span><span class="n">stop_words</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">count</span><span class="p">(</span><span class="n">docdate</span><span class="p">,</span><span class="w"> </span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">sort</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="kc">TRUE</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">ungroup</span><span class="p">()</span><span class="w"> </span></code></pre></div></div> <p>To feed our data to a clustering model - we will use the topicmodels package -, we need the data to be in the form of a <a href="https://en.wikipedia.org/wiki/Document-term_matrix">Document Term Matrix</a>. The cast_dtm() function in the tidytext package allows us to tint our speech data into a one-token-per-row table of the matriculation DocumentTermMatrix.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">speeches_2016_dtm</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">speeches_2016_unnest_tokens</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">cast_dtm</span><span class="p">(</span><span class="n">docdate</span><span class="p">,</span><span class="w"> </span><span class="n">word</span><span class="p">,</span><span class="w"> </span><span class="n">n</span><span class="p">)</span><span class="w"> </span><span class="nf">class</span><span class="p">(</span><span class="n">speeches_2016_dtm</span><span class="p">)</span><span class="w"> </span><span class="c1"># [1] "DocumentTermMatrix" "simple_triplet_matrix"</span><span class="w"> </span></code></pre></div></div> <p>Once we have our Document Term Matrix in place, we can let the <a href="https://cran.r-project.org/web/packages/topicmodels/index.html">Topicmodels</a> package do the rest of the work, and cluster each speech.Surpassingwe do this however, we want to segregate an towardly k value. k describes the number of clusters we want the model to bin our speech documents by. In this specimen we chose 15. However this number is arbitrary. In fact, what we see is that there are really 5 main clusters, the biggest one concerns people. However, as we only observing here the most frequent appearances, we should be shielding to rely too heavily on the most frequent instead of subsequent most frequent terms.</p> <p>Most frequent terms our cluster model identified: <img src="https://benheubl.github.io/images/strategy-to-speak/plots/cluster_algorythm2.jpeg" alt="pic1" /></p> <p>For a variegated approach, we could play virtually with k. In a new specimen scenario, we might want to classify and set k to 3. An explaination why we do so, can be found in the code. We refer to the “<a href="https://en.wikipedia.org/wiki/Determining_the_number_of_clusters_in_a_data_set">elbow method</a>”.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">topicmodel_hillary</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">LDA</span><span class="p">(</span><span class="n">speeches_2016_dtm</span><span class="p">,</span><span class="w"> </span><span class="n">k</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">3</span><span class="p">,</span><span class="w"> </span><span class="n">control</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">list</span><span class="p">(</span><span class="n">seed</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">100</span><span class="p">))</span><span class="w"> </span><span class="n">hillary_lda_gamma</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">tidytext</span><span class="o">:::</span><span class="n">tidy.LDA</span><span class="p">(</span><span class="n">topicmodel_hillary</span><span class="p">,</span><span class="w"> </span><span class="n">matrix</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"gamma"</span><span class="p">)</span><span class="w"> </span><span class="nf">class</span><span class="p">(</span><span class="n">hillary_lda_gamma</span><span class="p">)</span><span class="w"> </span><span class="c1"># [1] "tbl_df" "tbl" "data.frame"</span><span class="w"> </span><span class="n">hillary_lda_gamma</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hillary_lda_gamma</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">document</span><span class="w"> </span><span class="o">!=</span><span class="w"> </span><span class="s2">"May 19, 2015"</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">gamma</span><span class="w"> </span><span class="o">></span><span class="w"> </span><span class="m">0.9</span><span class="p">)</span><span class="w"> </span><span class="c1"># we filter the ones with a upper gamma value</span><span class="w"> </span><span class="n">topicmodel_hillary_tidydata</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">tidytext</span><span class="o">:::</span><span class="n">tidy.LDA</span><span class="p">(</span><span class="n">topicmodel_hillary</span><span class="p">)</span><span class="w"> </span><span class="n">topic_terms_1</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">topicmodel_hillary_tidydata</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">topic</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">top_n</span><span class="p">(</span><span class="m">1</span><span class="p">,</span><span class="w"> </span><span class="n">beta</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">ungroup</span><span class="p">()</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">arrange</span><span class="p">(</span><span class="n">topic</span><span class="p">,</span><span class="w"> </span><span class="o">-</span><span class="n">beta</span><span class="p">)</span><span class="w"> </span><span class="n">hillary_lda_gamma</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">hillary_lda_gamma</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">inner_join</span><span class="p">(</span><span class="n">topic_terms_1</span><span class="p">)</span><span class="w"> </span><span class="n">ggplot</span><span class="p">(</span><span class="n">hillary_lda_gamma</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">as.Date</span><span class="p">(</span><span class="n">document</span><span class="p">,</span><span class="w"> </span><span class="s2">"%B%d, %Y "</span><span class="p">),</span><span class="w"> </span><span class="n">fill</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">as.factor</span><span class="p">(</span><span class="n">topic</span><span class="p">)))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_bar</span><span class="p">(</span><span class="n">show.legend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">T</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">position</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"fill"</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ylim</span><span class="p">(</span><span class="m">0</span><span class="p">,</span><span class="w"> </span><span class="m">1</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme_bw</span><span class="p">()</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">scale_colour_brewer</span><span class="p">(</span><span class="n">palette</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s2">"Set1"</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme</span><span class="p">(</span><span class="w"> </span><span class="n">axis.text.y</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">element_blank</span><span class="p">(),</span><span class="w"> </span><span class="n">axis.ticks</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">element_blank</span><span class="p">())</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ylab</span><span class="p">(</span><span class="s2">""</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">xlab</span><span class="p">(</span><span class="s2">"2016, time speeches were given"</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>If we run this in ggplot, we can see that Hillary had three unshared groups of speeches. Cluster one is concerned with the people and presidency (in red), cluster two on the job market and the country, and a third one on Donald Trump (showing up correctly in undecorous in most recent times when she must have mentioned him most frequently, in the midst of the wayfarers race). <img src="https://benheubl.github.io/images/strategy-to-speak/plots/time_speeches.jpeg" alt="pic1" /></p> <h2 id="clustering-with-k-means">Clustering with K-means</h2> <p>Clustering with k-means is flipside unsupervised nomenclature method. Again, the reservation is that the matriculation labels obtained from an unsupervised classier are without intrinsic meaning, and needs our domain knowledge for labelling. This time we make use of the <a href="https://stat.ethz.ch/R-manual/R-devel/library/stats/html/00Index.html">stats package</a>. For this, our previous document-term matrix is perfect as an input.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="n">library</span><span class="p">(</span><span class="n">stats</span><span class="p">)</span><span class="w"> </span><span class="c1"># set k</span><span class="w"> </span><span class="n">set.seed</span><span class="p">(</span><span class="m">1000</span><span class="p">)</span><span class="w"> </span><span class="n">topicmodel_hillary_kmeans</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">kmeans</span><span class="p">(</span><span class="n">speeches_2016_dtm</span><span class="p">,</span><span class="w"> </span><span class="m">3</span><span class="p">)</span><span class="w"> </span><span class="c1"># creates a kmeans object</span><span class="w"> </span><span class="nf">class</span><span class="p">(</span><span class="n">topicmodel_hillary_kmeans</span><span class="p">)</span><span class="w"> </span><span class="c1"># [1] "kmeans"</span><span class="w"> </span><span class="c1"># The distribution of the clusters</span><span class="w"> </span><span class="n">topicmodel_hillary_kmeans</span><span class="o">$</span><span class="n">size</span><span class="w"> </span><span class="c1"># [1] 42 1 4</span><span class="w"> </span><span class="n">topicmodel_hillary_kmeans</span><span class="o">:</span><span class="w"> </span><span class="p">(</span><span class="n">Here</span><span class="w"> </span><span class="n">the</span><span class="w"> </span><span class="n">percentage</span><span class="w"> </span><span class="n">of</span><span class="w"> </span><span class="n">variance</span><span class="w"> </span><span class="n">is</span><span class="w"> </span><span class="n">calculated</span><span class="w"> </span><span class="n">as</span><span class="w"> </span><span class="n">the</span><span class="w"> </span><span class="n">ratio</span><span class="w"> </span><span class="n">of</span><span class="w"> </span><span class="n">the</span><span class="w"> </span><span class="n">between</span><span class="o">-</span><span class="n">group</span><span class="w"> </span><span class="n">variance</span><span class="w"> </span><span class="n">to</span><span class="w"> </span><span class="n">the</span><span class="w"> </span><span class="n">total</span><span class="w"> </span><span class="n">variance</span><span class="p">)</span><span class="w"> </span><span class="c1">#If we want to summate the sum of squares by cluster</span><span class="w"> </span><span class="n">topicmodel_hillary_kmeans</span><span class="o">$</span><span class="n">betweenss</span><span class="w"> </span><span class="o">/</span><span class="n">topicmodel_hillary_kmeans</span><span class="o">$</span><span class="n">tots</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.8553458</span><span class="w"> </span><span class="n">or</span><span class="w"> </span><span class="m">85.53</span><span class="o">% # for k = 2, we get: 79.4 %</span><span class="p">,</span><span class="w"> </span><span class="k">for</span><span class="w"> </span><span class="m">3</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">85.5</span><span class="w"> </span><span class="o">%, for 4 = 87.36 and for 5 = 88.13 %</span><span class="w"> </span><span class="p">(</span><span class="n">we</span><span class="w"> </span><span class="n">could</span><span class="w"> </span><span class="n">locate</span><span class="w"> </span><span class="n">the</span><span class="w"> </span><span class="s2">"elbow"</span><span class="w"> </span><span class="n">at</span><span class="w"> </span><span class="n">k</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">3</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>We chose k = 3 equal to the Elbow method, that looks at the percentage of variance explained as a function of the number of clusters. One should segregate a number of clusters so that subtracting flipside cluster doesn’t requite much largest modeling of the data.</p> <p>The data given by x are clustered by the k-means method, which aims to partition the points into k groups such that the sum of squares from points to the prescribed cluster centers is minimized. At the minimum, all cluster centers are at the midpoint of their Voronoi sets. We see that the model binned the speeches somewhat unevenly.</p> <div class="language-r highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="c1"># We use data.table to get the clusters and dates of our documents into a df</span><span class="w"> </span><span class="n">library</span><span class="p">(</span><span class="n">data.table</span><span class="p">)</span><span class="w"> </span><span class="n">df</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">as.data.frame</span><span class="p">(</span><span class="n">topicmodel_hillary_kmeans</span><span class="o">$</span><span class="n">cluster</span><span class="p">)</span><span class="w"> </span><span class="n">setDT</span><span class="p">(</span><span class="n">df</span><span class="p">,</span><span class="w"> </span><span class="n">keep.rownames</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="kc">TRUE</span><span class="p">)[]</span><span class="w"> </span><span class="nf">names</span><span class="p">(</span><span class="n">df</span><span class="p">)[</span><span class="m">1</span><span class="p">]</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="s2">"docdate"</span><span class="w"> </span><span class="nf">names</span><span class="p">(</span><span class="n">df</span><span class="p">)[</span><span class="m">2</span><span class="p">]</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="s2">"cluster"</span><span class="w"> </span><span class="c1"># Perform an inner join:</span><span class="w"> </span><span class="n">speeches_2016_unnest_tokens_join</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">speeches_2016_unnest_tokens</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">inner_join</span><span class="p">(</span><span class="n">df</span><span class="p">)</span><span class="w"> </span><span class="c1"># Show clusters in speeches over time, and most frequent words:</span><span class="w"> </span><span class="n">speeches_2016_unnest_tokens_join_plot</span><span class="w"> </span><span class="o"><-</span><span class="w"> </span><span class="n">speeches_2016_unnest_tokens_join</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">group_by</span><span class="p">(</span><span class="n">docdate</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">top_n</span><span class="p">(</span><span class="n">n</span><span class="o">=</span><span class="m">1</span><span class="p">)</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">summarise</span><span class="p">(</span><span class="n">cluster</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="p">(</span><span class="n">mean</span><span class="p">(</span><span class="n">cluster</span><span class="p">)),</span><span class="w"> </span><span class="n">wordmax</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="p">(</span><span class="nf">max</span><span class="p">(</span><span class="n">n</span><span class="p">,</span><span class="w"> </span><span class="n">word</span><span class="p">)),</span><span class="w"> </span><span class="n">max</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">max</span><span class="p">(</span><span class="n">n</span><span class="p">))</span><span class="w"> </span><span class="o">%>%</span><span class="w"> </span><span class="n">filter</span><span class="p">(</span><span class="n">docdate</span><span class="w"> </span><span class="o">!=</span><span class="w"> </span><span class="s2">"May 19, 2015"</span><span class="p">)</span><span class="w"> </span><span class="n">ggplot</span><span class="p">(</span><span class="n">speeches_2016_unnest_tokens_join_plot</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">as.Date</span><span class="p">(</span><span class="n">docdate</span><span class="p">,</span><span class="w"> </span><span class="s2">"%B%d, %Y "</span><span class="p">),</span><span class="w"> </span><span class="n">y</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.5</span><span class="p">,</span><span class="w"> </span><span class="n">col</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">as.factor</span><span class="p">(</span><span class="n">cluster</span><span class="p">),</span><span class="w"> </span><span class="n">size</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">max</span><span class="p">,</span><span class="w"> </span><span class="n">show.legend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_point</span><span class="p">(</span><span class="n">show.legend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">scale_size</span><span class="p">(</span><span class="n">range</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nf">c</span><span class="p">(</span><span class="m">0</span><span class="p">,</span><span class="w"> </span><span class="m">30</span><span class="p">))</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ylim</span><span class="p">(</span><span class="m">0</span><span class="p">,</span><span class="w"> </span><span class="m">1</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme_bw</span><span class="p">()</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">geom_label_repel</span><span class="p">(</span><span class="n">show.legend</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="nb">F</span><span class="p">,</span><span class="w"> </span><span class="n">aes</span><span class="p">(</span><span class="n">as.Date</span><span class="p">(</span><span class="n">docdate</span><span class="p">,</span><span class="w"> </span><span class="s2">"%B%d, %Y "</span><span class="p">),</span><span class="w"> </span><span class="n">y</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="m">0.5</span><span class="p">,</span><span class="w"> </span><span class="n">fill</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">factor</span><span class="p">(</span><span class="n">cluster</span><span class="p">),</span><span class="w"> </span><span class="n">label</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="p">(</span><span class="n">wordmax</span><span class="p">)),</span><span class="w"> </span><span class="n">fontface</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s1">'bold'</span><span class="p">,</span><span class="w"> </span><span class="n">color</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="s1">'white'</span><span class="p">,</span><span class="w"> </span><span class="n">box.padding</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">unit</span><span class="p">(</span><span class="m">0.25</span><span class="p">,</span><span class="w"> </span><span class="s2">"lines"</span><span class="p">),</span><span class="w"> </span><span class="n">point.padding</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">unit</span><span class="p">(</span><span class="m">0.5</span><span class="p">,</span><span class="w"> </span><span class="s2">"lines"</span><span class="p">)</span><span class="w"> </span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">theme</span><span class="p">(</span><span class="w"> </span><span class="n">axis.text.y</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">element_blank</span><span class="p">(),</span><span class="w"> </span><span class="n">axis.ticks</span><span class="w"> </span><span class="o">=</span><span class="w"> </span><span class="n">element_blank</span><span class="p">())</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">ylab</span><span class="p">(</span><span class="s2">""</span><span class="p">)</span><span class="w"> </span><span class="o">+</span><span class="w"> </span><span class="n">xlab</span><span class="p">(</span><span class="s2">"2016, stage speeches were given"</span><span class="p">)</span><span class="w"> </span></code></pre></div></div> <p>Most frequent terms our cluster model identified with the K-means clustering model: <img src="https://benheubl.github.io/images/strategy-to-speak/plots/cluster_kmeans.jpeg" alt="pic1" /> We get a somewhat variegated result. We see that it whimsically reflects the rally.Withoutthe institute in August the matriculation changes from untried to undecorous in the previous model, but here we see little change. Hillary talked much increasingly well-nigh Trump, and as she knows that she is now the final opponent, she should transpiration her topics accordingly. The untried rainbow is a bit flawed, as it comprises multiple speeches given on the same date. We can observe that our k-means model has some difficulties to cluster the speeches in equal bins. This could imply that speeches may have been very similar wideness her wayfarers rally, or a poor selection of k and the sparsity of wipe data.</p> <h1 id="wrapping-up">Wrapping up</h1> <p>In this post we learned that Hillary’s strategy to speak is one that remains on the positive side, that her latest wayfarers speeches must have featured increasingly emotional language in 2016 than in 2008, which increased the spread for sentences’s sentiment scores. We moreover understand now how she compares to other speakers at the presidential convention, and Barack Obama for the wayfarers speeches. She is not a copycat, and her speech varies considerably. We saw vestige on her standing on women’s rights, an overview of the key topics she covered in her 2016 wayfarers rally, and how they relate to assaults on her opponent Trump.</p> <p>We moreover learned that it might be harder to correctly classify her speeches into equal groups with k-mean and that Latent Dirichlet typecasting with the topicmodels package might be a largest nomination for topic classification. As we managed to wield machine leaning to get a rough idea of possible labels with LDA, that included children and the future, the job market, country domestic matters, Israel and a large group for the rest (mainly concerning voters issues), we didn’t manage to success with k-means.</p> <p>NLP is hard, and there is a long way to go to finally wield this to data journalism on a large scale. I can’t wait to publish the next post :-)</p>Ben Heubltechjournalism@gmail.comText wringer in R on speeches is one way to find some new untold stories in the presidential referendum discussion. In this post we will concentrate on Hillary Clinton and her strategy to speak